從云數(shù)據(jù)遷移服務看MySQL大表抽取模式的原理解析
摘要:MySQL JDBC抽取到底應該采用什么樣的方式,且聽小編給你娓娓道來。
小編最近在云上的一個遷移項目中被MySQL抽取模式折磨的很慘。一開始爆內(nèi)存被客戶懟,再后來遷移效率低下再被懟。MySQL JDBC抽取到底應該采用什么樣的方式,且聽小編給你娓娓道來。
1.1 Java-JDBC通信原理JDBC與數(shù)據(jù)庫之間的通信是通過socket完,大致流程如下圖所示。Mysql Server ->內(nèi)核Socket Buffer -> 客戶端Socket Buffer ->JDBC所在的JVM
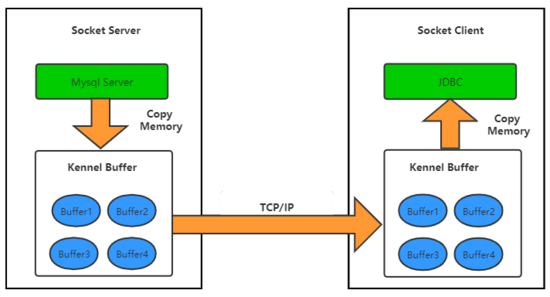
主要分為以下幾步:
1)Mysql Server通過OuputStream 向 Socket Server 本地Kennel Buffer 寫入數(shù)據(jù),這里是一次內(nèi)存拷貝。
2)當Socket Server 本地Kennel Buffer 有數(shù)據(jù),就會通過TCP鏈路把數(shù)據(jù)傳輸?shù)絊ocket Client 所在機器的Kennel Buffer。
3)JDBC 所在JVM利用InputSream讀取本地Kennel Buffer 數(shù)據(jù)到JVM內(nèi)存,沒有數(shù)據(jù)時,則讀取被阻塞。
接下來就是不斷重復1,2,3的過程。 問題 是,Socket Client 端的JVM在默認模式下讀取Kennel Buffer是沒有考慮本機內(nèi)存大小的,有多少讀多少。如果數(shù)據(jù)太大,就會造成FULL GC,緊接著內(nèi)存溢出。
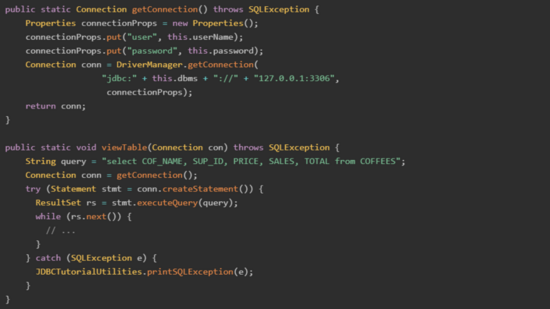
參考 JDBC API docs,默認模式 Java demo 代碼如下
為了解決方式1爆內(nèi)存的問題,JDBC提供了一個游標參數(shù),在建立jdbc連接時加上useCursorFetch=true。設置游標后,JDBC 每次會告訴Server端每次抽取的數(shù)據(jù)量,避免爆內(nèi)存。通信過程如下圖所示。
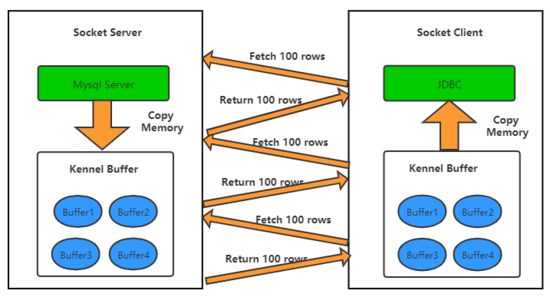
方式2游標查詢雖然解決了內(nèi)存溢出的問題,方式2極大的依賴網(wǎng)絡質量。當網(wǎng)絡時延增大,假設每次通信增加10ms,10萬次通信就會多出1000s。這里僅僅是每次發(fā)請求的RT,TCP每次發(fā)送報文,都要求反饋ACK保證數(shù)據(jù)可靠性。client每取100行(請求行數(shù)可配置),就會有多次通信,進一步放大時延增加導致的效率問題。此外,游標查詢下,Mysql無法預知查詢的結束時延,為了應對自身的DML操作會在本地建立一個臨時空間存放要抽取的數(shù)據(jù)。因此,游標查詢時會有以下幾個現(xiàn)象發(fā)生
a. IOPS飆升,Mysql將數(shù)據(jù)寫入到臨時空間,數(shù)據(jù)傳輸時從臨時空間讀取數(shù)據(jù),這都會引發(fā)大量IO操作。
b. 磁盤空間飆升,臨時空間生命周期存在于整個JDBC讀取階段,直到客戶端發(fā)起Result.close()時才會被Mysql回收。
c. CPU和內(nèi)存有一定比例上升。
有關游標查詢的原理可參考博客MySQL JDBC StreamResult通信原理淺析以及JDBC源碼,本文不在贅述。
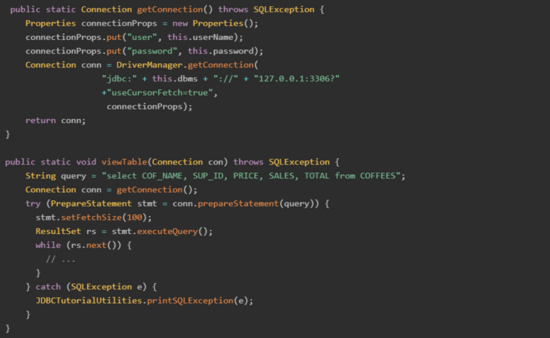
參考 JDBC API docs,游標模式 Java demo 代碼如下
方式1會導致JVM內(nèi)存溢出,方式2雖然不會FULL GC但是通信效率較低,而且也會導致Mysql服務端IOPS飆升,消耗磁盤空間等問題。因此,我們介紹Stream讀取數(shù)據(jù) ,流式需要在讀取Result前設置

方式3在通信前不會做任何Server-Cient的交互操作,避免通信效率低下。服務端準備好數(shù)據(jù)寫入Server的Kennel Buffer中,這些數(shù)據(jù)通過TCP鏈路傳輸?shù)紺lient的Kennel Buffer中,緊接著client端inputStream.read()方法被喚醒去讀取數(shù)據(jù),與方式1不同,client每次只會讀取一個package大小的數(shù)據(jù),如果一個package不滿一行則會再讀取一個package。當client消費數(shù)據(jù)的速度不及數(shù)據(jù)傳輸速率時,client端kennel區(qū)的數(shù)據(jù)就會被堆滿,緊接著Server端的kennel數(shù)據(jù)也會堆滿進而阻塞了OuputStream。這樣,JDBC在Stream模式下就像一個水管連接兩個蓄水池,Client和Server達到一個平衡。
對于JDBC客戶端,由于每次都是從kennel讀取數(shù)據(jù),效率會比方式2高很多,每次讀取一小部分數(shù)據(jù)也不會導致JVM內(nèi)存溢出。對于服務端,Mysql每次都是往kennel寫數(shù)據(jù),無需建立臨時空間,不涉及IO讀取,服務端壓力也變小了。當然,方式3也有自己的問題,例如Stream流式時無法cancel,cancel不阻塞等等。
參考 JDBC API docs,網(wǎng)上很多教程需要設置useCursorFetch=trueResultSet.FETCH_REVERSE等,其實小編研究完JDBC驅動源碼后發(fā)現(xiàn),只需要設fetchSize=Integer. MIN_VALUE,其他配置均和默認配置保持一致即可。游標模式 Java demo 代碼如下

云數(shù)據(jù)遷移服務(Cloud Data Migration, CDM)是華為云上一個遷移工具,詳見 CDM官網(wǎng) ,小編則通過CDM介紹如何切換三種模式抽取數(shù)據(jù)。CDM默認使用的是方式3,流式抽取數(shù)據(jù),如果需要切換方式1,方式2需額外配置。
1.3.1 配置方式1:默認讀取新建Mysql連接器,建立方法詳見官網(wǎng),在高級屬性中增加useCursorFetch=false和adopt.stream=false
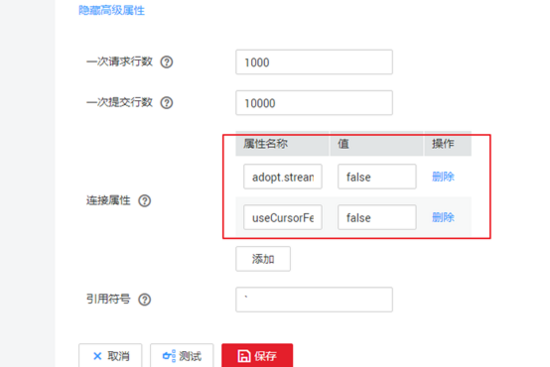
編輯Mysql連接器,在高級屬性中增加useCursorFetch=true和adopt.stream=false。游標查詢的大小可通過界面上的Fetch Size調整,默認1000。

CDM默認走的流式,無需額外配置。注意Stream模式下,界面上的 Fetch Size 是不起作用的,原因參考上一節(jié)。
1.3.4 性能對比新建Mysql2Hive的CDM遷移作業(yè),源表101個字段,100萬行數(shù)據(jù),配置如下
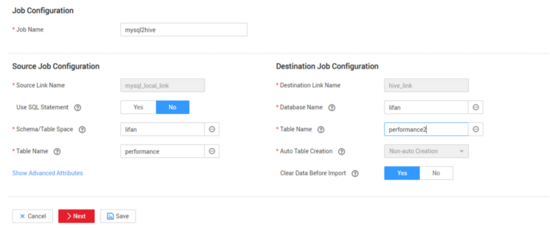
方式1:寫入100萬行數(shù)據(jù)耗時1m22s

方式2:同樣寫入100萬行,調整fetchSzie分別為1,10,100,100,最低耗時2m1s

方式3:同樣寫入100萬行,耗時1m5s

小編還測試了100萬的小表,明顯方式1和方式3的速率要遠遠高于方式2,另外小編還測試了1000萬的大表,方式1爆內(nèi)存,方式2正常遷移但耗時20分鐘以上,而方式3仍然可以在15分鐘內(nèi)跑完。
到此這篇關于從云數(shù)據(jù)遷移服務看MySQL大表抽取模式的原理解析的文章就介紹到這了,更多相關MySQL大表抽取內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持好吧啦網(wǎng)!
相關文章:
1. 詳解MySQL的Seconds_Behind_Master2. 一次SQL查詢優(yōu)化原理分析(900W+數(shù)據(jù)從17s到300ms)3. MySQL MyISAM 與InnoDB 的區(qū)別4. MySQL中建表時可空(NULL)和非空(NOT NULL)的用法詳解5. SQLite 實現(xiàn)if not exist 類似功能的操作6. Microsoft Office Access調整控件大小的方法7. Mysql入門系列:建立MYSQL客戶機程序的一般過程8. Mysql入門系列:MYSQL表達式求值和MYSQL類型轉換9. MySql遠程連接的實現(xiàn)方法10. 快速刪除ORACLE重復記錄
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備