如何把Spring Cloud Data Flow部署在Kubernetes上
1 前言
Spring Cloud Data Flow在本地跑得好好的,為什么要部署在Kubernetes上呢?主要是因?yàn)镵ubernetes能提供更靈活的微服務(wù)管理;在集群上跑,會(huì)更安全穩(wěn)定、更合理利用物理資源。
Spring Cloud Data Flow入門簡(jiǎn)介請(qǐng)參考:Spring Cloud Data Flow初體驗(yàn),以Local模式運(yùn)行
2 部署Data Flow到Kubernetes
以簡(jiǎn)單為原則,我們依然是基于Batch任務(wù),不部署與Stream相關(guān)的組件。
2.1 下載GitHub代碼
我們要基于官方提供的部署代碼進(jìn)行修改,先把官方代碼clone下來(lái):
$ git clone https://github.com/spring-cloud/spring-cloud-dataflow.git
我們切換到最新穩(wěn)定版本的代碼版本:
$ git checkout v2.5.3.RELEASE
2.2 創(chuàng)建權(quán)限賬號(hào)
為了讓Data Flow Server有權(quán)限來(lái)跑任務(wù),能在Kubernetes管理資源,如新建Pod等,所以要?jiǎng)?chuàng)建對(duì)應(yīng)的權(quán)限賬號(hào)。這部分代碼與源碼一致,不需要修改:
(1)server-roles.yaml
kind: RoleapiVersion: rbac.authorization.k8s.io/v1metadata: name: scdf-rolerules: - apiGroups: [''] resources: ['services', 'pods', 'replicationcontrollers', 'persistentvolumeclaims'] verbs: ['get', 'list', 'watch', 'create', 'delete', 'update'] - apiGroups: [''] resources: ['configmaps', 'secrets', 'pods/log'] verbs: ['get', 'list', 'watch'] - apiGroups: ['apps'] resources: ['statefulsets', 'deployments', 'replicasets'] verbs: ['get', 'list', 'watch', 'create', 'delete', 'update', 'patch'] - apiGroups: ['extensions'] resources: ['deployments', 'replicasets'] verbs: ['get', 'list', 'watch', 'create', 'delete', 'update', 'patch'] - apiGroups: ['batch'] resources: ['cronjobs', 'jobs'] verbs: ['create', 'delete', 'get', 'list', 'watch', 'update', 'patch']
(2)server-rolebinding.yaml
kind: RoleBindingapiVersion: rbac.authorization.k8s.io/v1beta1metadata: name: scdf-rbsubjects:- kind: ServiceAccount name: scdf-saroleRef: kind: Role name: scdf-role apiGroup: rbac.authorization.k8s.io
(3)service-account.yaml
apiVersion: v1kind: ServiceAccountmetadata: name: scdf-sa
執(zhí)行以下命令,創(chuàng)建對(duì)應(yīng)賬號(hào):
$ kubectl create -f src/kubernetes/server/server-roles.yaml $ kubectl create -f src/kubernetes/server/server-rolebinding.yaml $ kubectl create -f src/kubernetes/server/service-account.yaml
執(zhí)行完成后,可以檢查一下:
$ kubectl get roleNAME AGEscdf-role 119m$ kubectl get rolebindingNAME AGEscdf-rb 117m$ kubectl get serviceAccountNAME SECRETS AGEdefault 1 27dscdf-sa 1 117m
2.3 部署MySQL
可以選擇其它數(shù)據(jù)庫(kù),如果本來(lái)就有數(shù)據(jù)庫(kù),可以不用部署,在部署Server的時(shí)候改一下配置就好了。這里跟著官方的Guide來(lái)。為了保證部署不會(huì)因?yàn)殓R像下載問(wèn)題而失敗,我提前下載了鏡像:
$ docker pull mysql:5.7.25
MySQL的yaml文件也不需要修改,直接執(zhí)行以下命令即可:
$ kubectl create -f src/kubernetes/mysql/
執(zhí)行完后檢查一下:
$ kubectl get SecretNAME TYPE DATA AGEdefault-token-jhgfp kubernetes.io/service-account-token 3 27dmysql Opaque 2 98mscdf-sa-token-wmgk6 kubernetes.io/service-account-token 3 123m$ kubectl get PersistentVolumeClaimNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEmysql Bound pvc-e95b495a-bea5-40ee-9606-dab8d9b0d65c 8Gi RWO hostpath 98m$ kubectl get DeploymentNAME READY UP-TO-DATE AVAILABLE AGEmysql 1/1 1 1 98m$ kubectl get ServiceNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEmysql ClusterIP 10.98.243.130 <none> 3306/TCP 98m
2.4 部署Data Flow Server
2.4.1 修改配置文件server-config.yaml
刪除掉不用的配置,主要是Prometheus和Grafana的配置,結(jié)果如下:
apiVersion: v1kind: ConfigMapmetadata: name: scdf-server labels: app: scdf-serverdata: application.yaml: |- spring: cloud: dataflow: task: platform: kubernetes: accounts: default: limits: memory: 1024Mi datasource: url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/mysql username: root password: ${mysql-root-password} driverClassName: org.mariadb.jdbc.Driver testOnBorrow: true validationQuery: 'SELECT 1'
2.4.2 修改server-svc.yaml
因?yàn)槲沂潜镜剡\(yùn)行的Kubernetes,所以把Service類型從LoadBalancer改為NodePort,并配置端口為30093。
kind: ServiceapiVersion: v1metadata: name: scdf-server labels: app: scdf-server spring-deployment-id: scdfspec: # If you are running k8s on a local dev box or using minikube, you can use type NodePort instead type: NodePort ports: - port: 80 name: scdf-server nodePort: 30093 selector: app: scdf-server
2.4.3 修改server-deployment.yaml
主要把Stream相關(guān)的去掉,如SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI配置項(xiàng):
apiVersion: apps/v1kind: Deploymentmetadata: name: scdf-server labels: app: scdf-serverspec: selector: matchLabels: app: scdf-server replicas: 1 template: metadata: labels: app: scdf-server spec: containers: - name: scdf-server image: springcloud/spring-cloud-dataflow-server:2.5.3.RELEASE imagePullPolicy: IfNotPresent volumeMounts: - name: database mountPath: /etc/secrets/database readOnly: true ports: - containerPort: 80 livenessProbe: httpGet: path: /management/health port: 80 initialDelaySeconds: 45 readinessProbe: httpGet: path: /management/info port: 80 initialDelaySeconds: 45 resources: limits: cpu: 1.0 memory: 2048Mi requests: cpu: 0.5 memory: 1024Mi env: - name: KUBERNETES_NAMESPACE valueFrom: fieldRef: fieldPath: 'metadata.namespace' - name: SERVER_PORT value: ’80’ - name: SPRING_CLOUD_CONFIG_ENABLED value: ’false’ - name: SPRING_CLOUD_DATAFLOW_FEATURES_ANALYTICS_ENABLED value: ’true’ - name: SPRING_CLOUD_DATAFLOW_FEATURES_SCHEDULES_ENABLED value: ’true’ - name: SPRING_CLOUD_KUBERNETES_SECRETS_ENABLE_API value: ’true’ - name: SPRING_CLOUD_KUBERNETES_SECRETS_PATHS value: /etc/secrets - name: SPRING_CLOUD_KUBERNETES_CONFIG_NAME value: scdf-server - name: SPRING_CLOUD_DATAFLOW_SERVER_URI value: ’http://${SCDF_SERVER_SERVICE_HOST}:${SCDF_SERVER_SERVICE_PORT}’ # Add Maven repo for metadata artifact resolution for all stream apps - name: SPRING_APPLICATION_JSON value: '{ 'maven': { 'local-repository': null, 'remote-repositories': { 'repo1': { 'url': 'https://repo.spring.io/libs-snapshot'} } } }' initContainers: - name: init-mysql-wait image: busybox command: [’sh’, ’-c’, ’until nc -w3 -z mysql 3306; do echo waiting for mysql; sleep 3; done;’] serviceAccountName: scdf-sa volumes: - name: database secret: secretName: mysql
2.4.4 部署Server
完成文件修改后,就可以執(zhí)行以下命令部署了:
# 提前下載鏡像$ docker pull springcloud/spring-cloud-dataflow-server:2.5.3.RELEASE# 部署Data Flow Server$ kubectl create -f src/kubernetes/server/server-config.yaml $ kubectl create -f src/kubernetes/server/server-svc.yaml $ kubectl create -f src/kubernetes/server/server-deployment.yaml
執(zhí)行完成,沒(méi)有錯(cuò)誤就可以訪問(wèn):http://localhost:30093/dashboard/
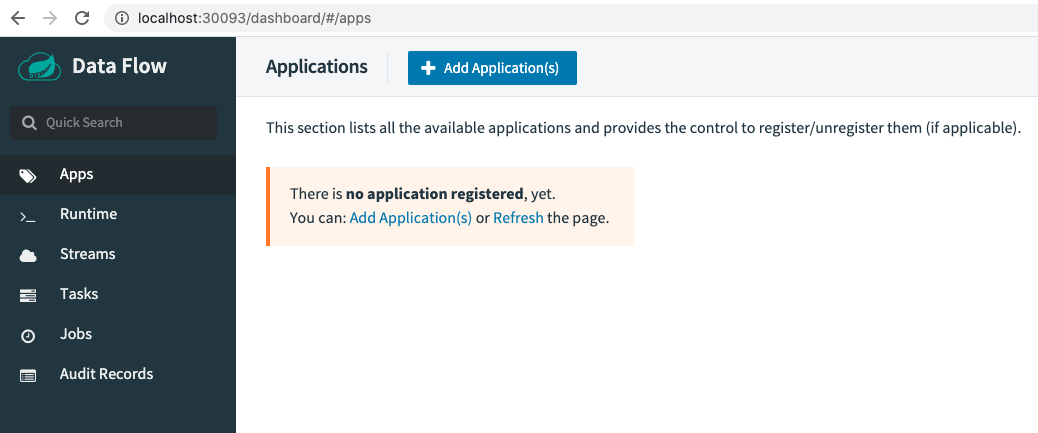
3 運(yùn)行一個(gè)Task
檢驗(yàn)是否部署成功最簡(jiǎn)單的方式就是跑一個(gè)任務(wù)試試。還是按以前的步驟,先注冊(cè)應(yīng)用,再定義Task,然后執(zhí)行。
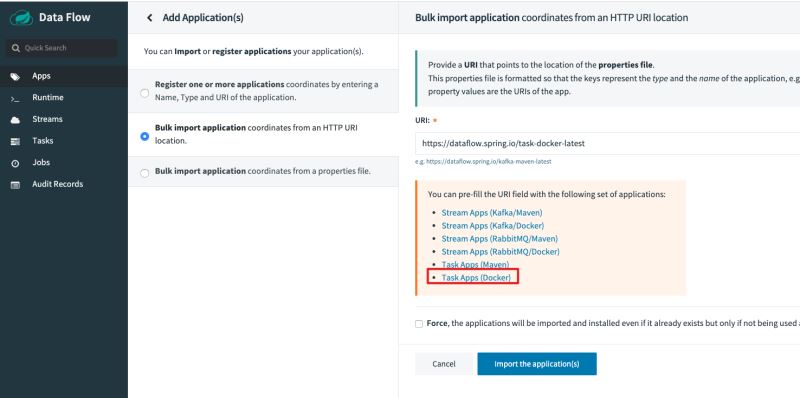
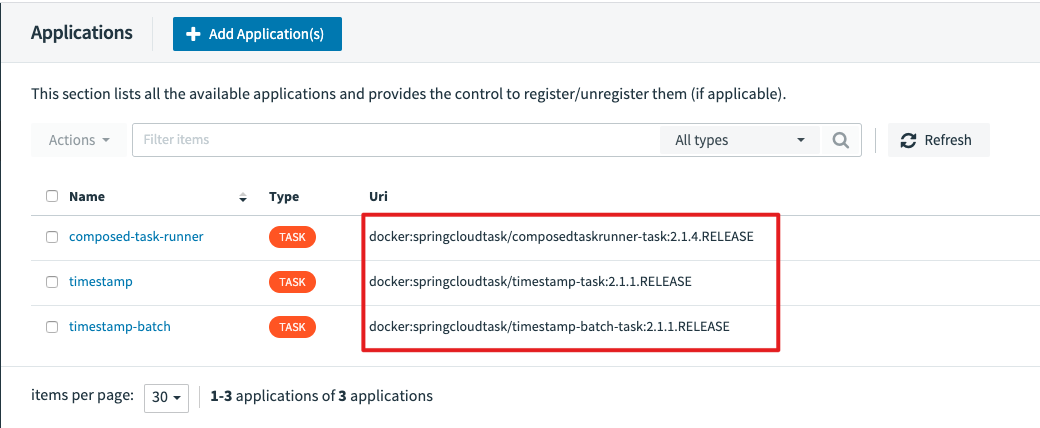
我們依舊使用官方已經(jīng)準(zhǔn)備好的應(yīng)用,但要注意這次我們選擇是的Docker格式,而不是jar包了。
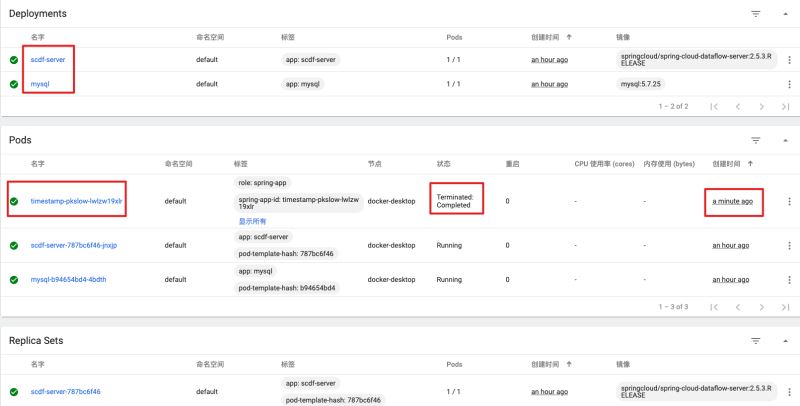
成功執(zhí)行后,查看Kubernetes的Dashboard,能看到一個(gè)剛創(chuàng)建的Pod:
4 總結(jié)
本文通過(guò)一步步講解,把Spring Cloud Data Flow成功部署在了Kubernetes上,并成功在Kubenetes上跑了一個(gè)任務(wù),再也不再是Local本地單機(jī)模式了。
到此這篇關(guān)于把Spring Cloud Data Flow部署在Kubernetes上,再跑個(gè)任務(wù)試試的文章就介紹到這了,更多相關(guān)把Spring Cloud Data Flow部署在Kubernetes上,再跑個(gè)任務(wù)試試內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. IntelliJ IDEA導(dǎo)入jar包的方法2. SSM框架JSP使用Layui實(shí)現(xiàn)layer彈出層效果3. 刪除docker里建立容器的操作方法4. IntelliJ IDEA導(dǎo)出項(xiàng)目的方法5. .Net中的Http請(qǐng)求調(diào)用詳解(Post與Get)6. 解決python DataFrame 打印結(jié)果不換行問(wèn)題7. java使用xfire搭建webservice服務(wù)的過(guò)程詳解8. Java導(dǎo)出Execl疑難點(diǎn)處理的實(shí)現(xiàn)9. python 調(diào)用API接口 獲取和解析 Json數(shù)據(jù)10. Python如何測(cè)試stdout輸出

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備