python實現scrapy爬蟲每天定時抓取數據的示例代碼
通過以下三步,保證爬蟲能自動隔天抓取數據: 每天凌晨00:01啟動監控腳本,監控爬蟲的運行狀態,一旦爬蟲進入空閑狀態,啟動爬蟲。
一旦爬蟲執行完畢,自動退出腳本,結束今天的任務。
一旦腳本距離啟動時間超過24小時,自動退出腳本,等待第二天的監控腳本啟動,重復這三步。
2. 環境。python 3.6.1
系統:win7
IDE:pycharm
安裝過scrapy
3. 設計思路。3.1. 前提:
目前爬蟲是通過scrapy模塊自帶的cmdline.execute來啟動的。
from scrapy import cmdlinecmdline.execute(’scrapy crawl mySpider’.split())
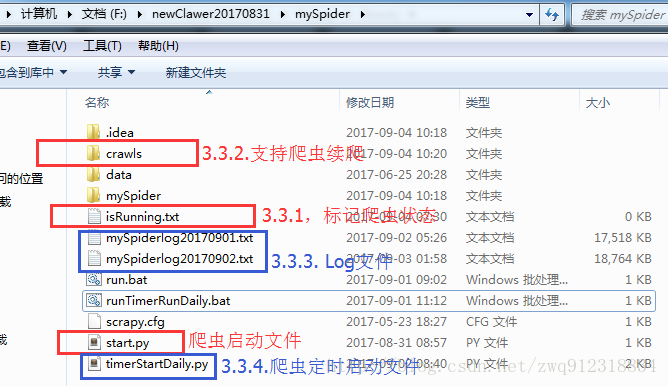
3.2. 將自動執行腳本做到scrapy爬蟲的外部
(1)每天凌晨00:01啟動腳本(控制腳本的存活時間為24小時),監測爬蟲的運行狀態(需要用一個標記信息來表示爬蟲的狀態:運行還是停止)。
如果爬蟲處于運行狀態(前一天爬取數據尚未結束),進入第(2)步; 如果爬蟲處于非運行狀態(前一天的爬取任務已完成,今天的尚未開始),進入第(3)步;(2)腳本進入等待階段,每隔10分鐘,檢查一下爬蟲的運行狀態,如(1)。但是一旦發現,腳本的等待時間超過了24小時,則自動退出腳本,因為第二天的監測腳本已經開始運行了,接替了它的任務。
(3)做一些爬蟲啟動前的準備工作(刪除用來續爬的文件,防止爬蟲不運行了),啟動爬蟲爬取數據,待爬蟲正常結束后,退出腳本,完成當天的爬取任務。
4. 準備工作。4.1. 標記爬蟲的運行狀態。通過判斷文件是否存在的方式來判斷爬蟲是否處于運行狀態:
在爬蟲啟動時,創建一個isRunning.txt文件。 在爬蟲結束時,刪除這個isRunning.txt文件。那么isRunning.txt存在,就說明爬蟲正在運行;文件不存在,就說明爬蟲不在運行。
# 文件pipelines.py# 爬蟲啟動時checkFile = 'isRunning.txt'class myPipeline: def open_spider(self, spider): self.client = MongoClient(’localhost:27017’) # 連接Mongodb self.db = self.client[’mydata’]# 待存儲數據的數據庫mydata f = open(checkFile, 'w') # 創建一個文件,代表爬蟲在運行中 f.close()
# 文件pipelines.py# 爬蟲正常結束時checkFile = 'isRunning.txt'class myPipeline: def close_spider(self, spider): self.client.close() isFileExsit = os.path.isfile(checkFile) if isFileExsit: os.remove(checkFile)4.2. 爬蟲支持續爬,能隨時暫停,方便調試。
# 在scrapy項目中添加start.py文件,用于啟動爬蟲from scrapy import cmdline# 在爬蟲運行過程中,會自動將狀態信息存儲在crawls/storeMyRequest目錄下,支持續爬cmdline.execute(’scrapy crawl mySpider -s JOBDIR=crawls/storeMyRequest’.split())# Note:若想支持續爬,在ctrl+c終止爬蟲時,只能按一次,爬蟲在終止時需要進行善后工作,切勿連續多次按ctrl+c
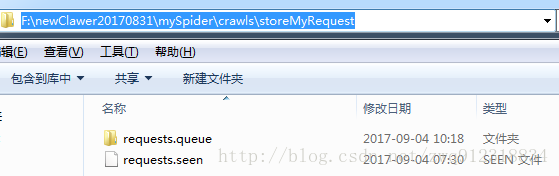
設置Log等級:
# 文件mySpider.pyclass mySpider(CrawlSpider): name = 'mySpider' allowed_domains = [’http://photo.poco.cn/’] custom_settings = { ’LOG_LEVEL’:’INFO’, # 減少Log輸出量,僅保留必要的信息 # ...... 在爬蟲內部用custom_setting可以讓這個配置信息僅對這一個爬蟲生效 }
以日期為Log文件命名
# 文件settings.pyimport datetimeBOT_NAME = ’mySpider’ROBOTSTXT_OBEY = FalsestartDate = datetime.datetime.now().strftime(’%Y%m%d’)LOG_FILE=f'mySpiderlog{startDate}.txt'
4.4. 為數據按日期存儲到不同的表(mongodb的集合)中
# 文件pipelines.pyimport datetimeGALANCE=f’galance{datetime.datetime.now().strftime('%Y%m%d')}’ # 表名
class myPipeline: def open_spider(self, spider): self.client = MongoClient(’localhost:27017’) # 連接Mongodb self.db = self.client[’mydata’]# 待存儲數據的數據庫mydata
self.db[GALANCE].insert(dict(item))
# 文件run.batcd /d F:/newClawer20170831/mySpidercall python main.pypause
# 文件timerStartDaily.pyfrom scrapy import cmdlineimport datetimeimport timeimport shutilimport osrecoderDir = r'crawls' # 這是為了爬蟲能夠續爬而創建的目錄,存儲續爬需要的數據checkFile = 'isRunning.txt' # 爬蟲是否在運行的標志startTime = datetime.datetime.now()print(f'startTime = {startTime}')i = 0miniter = 0while True: isRunning = os.path.isfile(checkFile) if not isRunning: # 爬蟲不在執行,開始啟動爬蟲 # 在爬蟲啟動之前處理一些事情,清掉JOBDIR = crawls isExsit = os.path.isdir(recoderDir) # 檢查JOBDIR目錄crawls是否存在 print(f'mySpider not running, ready to start. isExsit:{isExsit}') if isExsit: removeRes = shutil.rmtree(recoderDir) # 刪除續爬目錄crawls及目錄下所有文件 print(f'At time:{datetime.datetime.now()}, delete res:{removeRes}') else: print(f'At time:{datetime.datetime.now()}, Dir:{recoderDir} is not exsit.') time.sleep(20) clawerTime = datetime.datetime.now() waitTime = clawerTime - startTime print(f'At time:{clawerTime}, start clawer: mySpider !!!, waitTime:{waitTime}') cmdline.execute(’scrapy crawl mySpider -s JOBDIR=crawls/storeMyRequest’.split()) break #爬蟲結束之后,退出腳本 else: print(f'At time:{datetime.datetime.now()}, mySpider is running, sleep to wait.') i += 1 time.sleep(600) # 每10分鐘檢查一次 miniter += 10 if miniter >= 1440: # 等待滿24小時,自動退出監控腳本 break
5.2. 編寫bat批處理文件
# 文件runTimerRunDaily.batcd /d F:/newClawer20170831/mySpidercall python timerStartDaily.pypause6. 部署。6.1. 添加計劃任務。
參考以下這篇博客部署windows計劃任務:
https://www.jb51.net/article/204879.htm
有關windows計劃任務相關設置的詳細說明如下:
https://technet.microsoft.com/zh-cn/library/cc722178.aspx
6.2. 注意事項。(1)在添加計劃任務時,要按照如下圖進行勾選(只在用戶登錄時運行),才能彈出下面的cmd任務界面,方便觀察和調試。
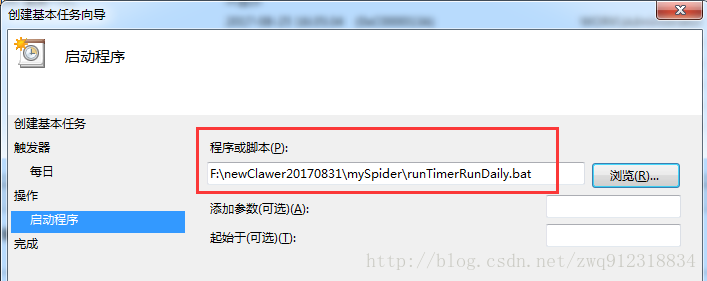
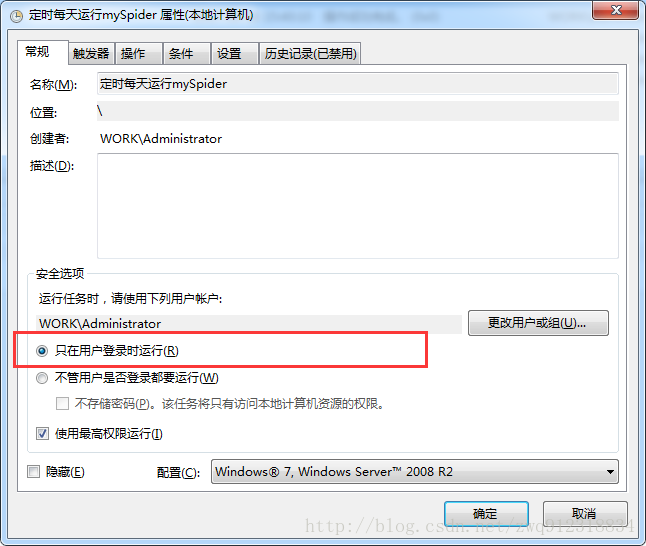
(2)由于爬蟲運行時間很長,如果按照默認設置,在凌晨運行實例時,上一次啟動尚未結束,會導致這次啟動失敗,所以要更改默認設置為(如果此任務已經運行:并行運行新實例。保護機制在于每個啟動腳本在等待24小時候會自動退出,來保證不會重復啟動)。
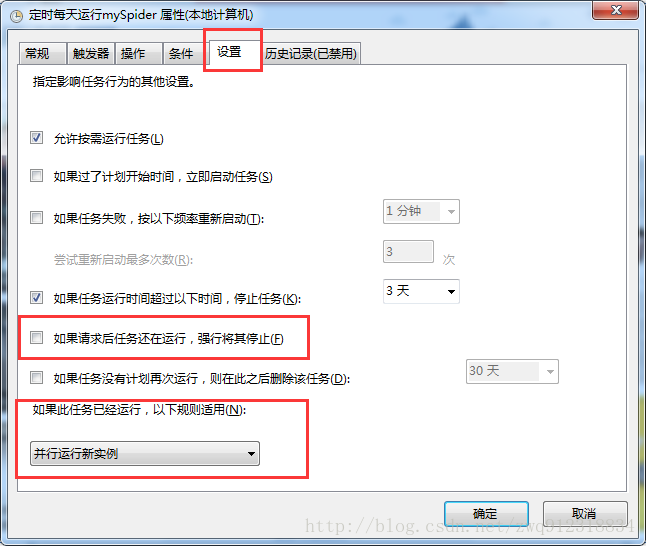
(3)如果想支持續傳,只能按一次 ctrl + c 來停止爬蟲運行。因為終止爬蟲時,爬蟲需要做一些善后工作,如果連續按多次ctrl + c來停止爬蟲,爬蟲將來不及善后,會導致無法續爬。 6.3. 效果展示。
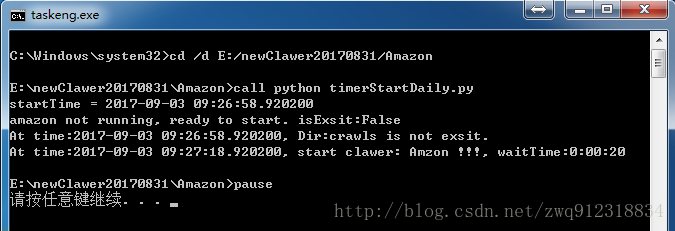
正常執行完成:
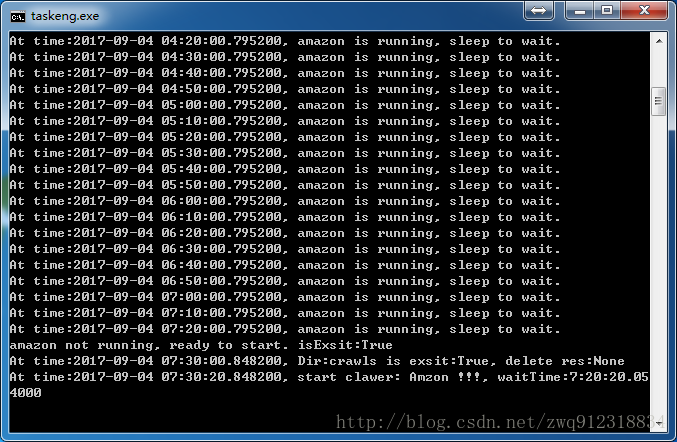
正在執行中:
到此這篇關于python實現scrapy爬蟲每天定時抓取數據的示例代碼的文章就介紹到這了,更多相關python scrapy定時抓取內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備