文章詳情頁
網頁爬蟲 - Python爬蟲返回狀態碼與實際情況不符?
瀏覽:230日期:2022-09-03 18:57:11
問題描述
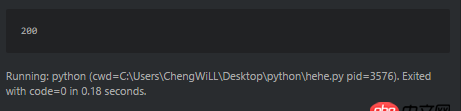
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如這個爬蟲,輸出狀態碼是200。
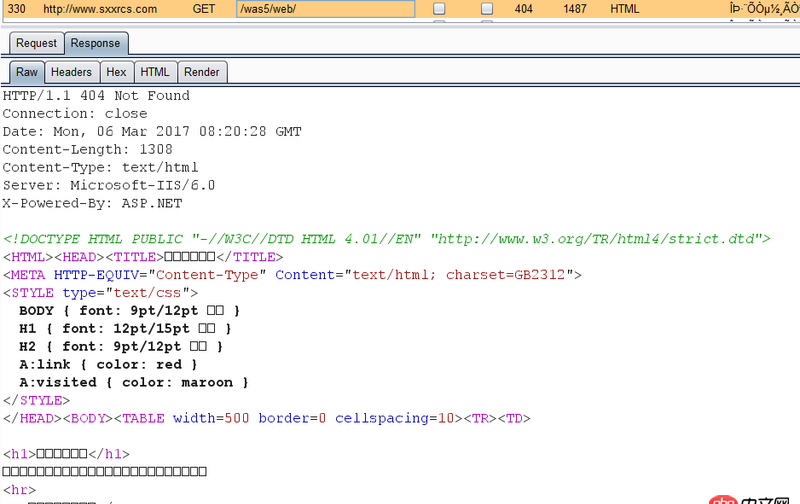
可是直接訪問http://www.sxxrcs.com/was5/web/是404,抓包響應的也是404,請問這是為什么?
問題解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相關文章:
1. angular.js - 各位大神們,你們混合開發,web方式中更推薦用什么框架呀? react?vue?angular?謝謝~2. angular.js - angularjs的自定義過濾器如何給文字加顏色?3. angular.js使用$resource服務把數據存入mongodb的問題。4. docker-machine添加一個已有的docker主機問題5. javascript - IOS微信audio標簽不能通過touchend播放6. html - 如何用css令背景圖能夠撐滿本身會滾動的頁面?7. 老師百度網盤分享一下WampServer的包啊,我們下載幾kb要下載一天的.8. javascript - htaccess rewrite 的問題9. 自己安裝了apache2.2,但是重啟apache后出錯了,求解!謝謝!10. html5 - vuex 為什么需要action,我發現進行異步操作回調中直接操作mutation也沒有報錯
排行榜
 網公網安備
網公網安備