java使用URLDecoder和URLEncoder對中文字符進行編碼和解碼
摘要:
URLDecoder 和 URLEncoder 用于完成普通字符串 和 application/x-www-form-urlencoded MIME 字符串之間的相互轉換。在本文中,我們以使用URLDecoder解決GET請求中文亂碼問題為場景說明 URLDecoder/URLEncoder 的用法,并給出了 application/x-www-form-urlencoded MIME 字符串的編碼規則。
一. URLDecoder/URLEncoder 使用場景概述
URLDecoder 和 URLEncoder 用于完成普通字符串 和 application/x-www-form-urlencoded MIME 字符串之間的相互轉換。在介紹 application/x-www-form-urlencoded MIME 字符串之前,我們先考慮如下場景,如下圖所示:

我們知道,在我們向客戶端發起請求時,瀏覽器會根據請求URL生成相應的請求報文發送給服務器。在這個過程中,如果我們在瀏覽器中的地址欄中所輸入的URL包含中文字符時,瀏覽器首先會將這些中文字符進行編碼然后再發送給服務器。實際上,瀏覽器會將它們轉換為 application/x-www-form-urlencoded MIME 字符串,如下圖所示:
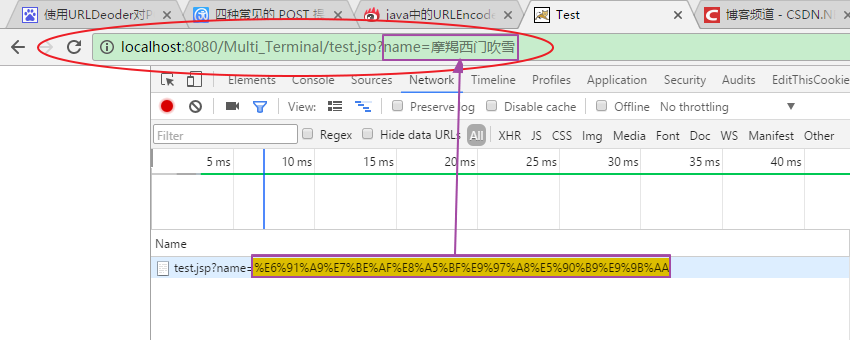
更確切的,當URL地址里包含非西歐字符的字符串時,瀏覽器都會將這些非西歐字符串轉換成application/x-www-form-urlencoded MIME 字符串。在開發過程中,我們可能涉及將普通字符串和這種特殊字符串的相關轉換,這就需要使用 URLDecoder 和 URLEncoder類進行實現,其中:
URLDecoder類包含一個decode(String s,String enc)靜態方法,它可以將application/x-www-form-urlencoded MIME字符串轉成普通字符串; URLEncoder類包含一個encode(String s,String enc)靜態方法,它可以將普通字符串轉換成application/x-www-form-urlencoded MIME字符串。下面程序示范了普通字符串轉與 application/x-www-form-urlencoded MIME 字符串之間的轉化。
public class URLDecoderTest { public static void main(String[] args) throws Exception { // 將application/x-www-form-urlencoded字符串轉換成普通字符串 // 其中的字符串直接從上圖所示窗口復制過來,chrome 默認用 UTF-8 字符集進行編碼,所以也應該用對應的字符集解碼 System.out.println('采用UTF-8字符集進行解碼:'); String keyWord = URLDecoder.decode('%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6+Rico', 'UTF-8'); System.out.println(keyWord); System.out.println('n 采用GBK字符集進行解碼:'); System.out.println(URLDecoder.decode('%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6+Rico', 'GBK')); // 將普通字符串轉換成application/x-www-form-urlencoded字符串 System.out.println('n 采用utf-8字符集:'); String urlStr = URLEncoder.encode('天津大學', 'utf-8'); System.out.println(urlStr); System.out.println('n 采用GBK字符集:'); String urlStr2 = URLEncoder.encode('天津大學', 'GBK'); System.out.println(urlStr2); }}/* Output: 采用UTF-8字符集進行解碼: 天津大學 Rico 采用GBK字符集進行解碼: 澶╂觸澶у? Rico 采用utf-8字符集: %E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6 采用GBK字符集: %CC%EC%BD%F2%B4%F3%D1%A7 *///:~
特別地,僅包含西歐字符的普通字符串和application/x-www-form-urlencoded MIME字符串無須轉換,而包含中文字符的普通字符串則需要轉換,轉換的方法是每個中文字符占2個字節,每個字節可以轉換成2個十六進制的數字,所以每個中文字符將轉換成“%XX%XX”的形式。當然,采用不同的字符集時,每個中文字符對應的字節數并不完全相同,所以使用URLEncoder和URLDecoder進行轉換時也需要指定字符集。特別地,字符串應以同樣的字符集進行編碼和解碼,否則會產生意想不到的結果,如上述程序示例所示。
二. 解決GET請求中文亂碼問題
URLDecoder的一個應用場景就是解決GET請求的中文亂碼問題,如下述代碼所示:
<%@page import='java.net.URLDecoder'%><%@ page language='java' import='java.util.*' pageEncoding='UTF-8'%><html><head> <title>Test</title></head><body> <% String param1 = request.getQueryString(); String param2 = URLDecoder.decode(param1, 'utf-8'); out.print(param2.split('=')[1] + '<br>'); %></body></html>
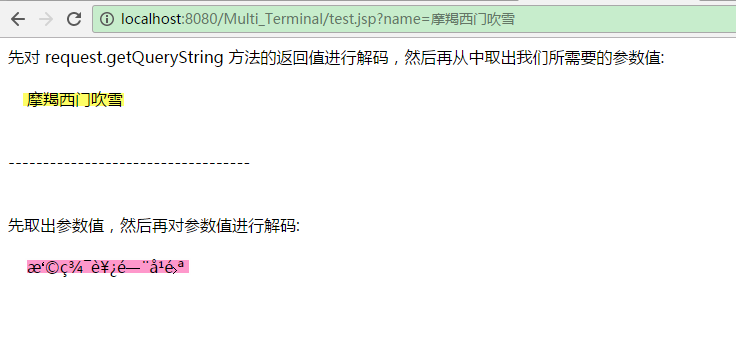
特別需要注意的是,使用此方式對GET請求參數進行解碼時,我們必須先對 request.getQueryString 方法的返回值(例如,“name=摩羯西門吹雪”)進行解碼,然后再從中取出我們所需要的參數值。如果先取出參數值,然后再對參數值進行解碼,則我們將得到亂碼,如下圖所示:
此外,對于包含中文字符的POST請求參數,我們只需在獲取請求參數前通過以下代碼語句進行轉碼即可:
request.setCharacterEncoding('utf-8');
三. URLEncoder & URLDecoder
對 String 編碼時,使用以下規則:
字母、數字和字符, “a” 到 “z”、”A” 到 “Z” 和 “0” 到 “9” 保持不變; 特殊字符 “.”、”-“、”*” 和 “_” 保持不變; 空格字符 ” ” 轉換為一個加號 “+”。除此之外,所有的其他字符都是不安全的。因此需要使用一些編碼機制將它們轉換為一個或多個字節,每個字節用一個包含 3 個字符的字符串 “%xy” 表示,其中 xy 為該字節的兩位十六進制表示形式,推薦的編碼機制是 UTF-8。例如,使用 UTF-8 編碼機制,字符串 “The string ü@foo-bar” 將轉換為 “The+string+%C3%BC%40foo-bar”,因為在 UTF-8 中,字符 ü 編碼為兩個字節,C3 (十六進制)和 BC (十六進制),字符 @ 編碼為一個字節 40 (十六進制)。
關于 URLDecoder 類的使用,轉換過程正好與 URLEncoder 類使用的過程相反,此不贅述。
關于JSP中文亂碼更多的介紹,包括 頁面亂碼、參數亂碼、表單亂碼、源文件亂碼 等知識,見我的另外兩篇博客:《JSP中文亂碼問題終極解決方案(上)》 和 《JSP中文亂碼問題終極解決方案(下)》。
引用
使用URLDecoder和URLEncoder對中文進行處理
到此這篇關于java使用URLDecoder和URLEncoder對中文字符進行編碼和解碼的文章就介紹到這了,更多相關java 文字符編碼解碼內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備