python 代碼實現k-means聚類分析的思路(不使用現成聚類庫)
一、實驗目標
1、使用 K-means 模型進行聚類,嘗試使用不同的類別個數 K,并分析聚類結果。
2、按照 8:2 的比例隨機將數據劃分為訓練集和測試集,至少嘗試 3 個不同的 K 值,并畫出不同 K 下 的聚類結果,及不同模型在訓練集和測試集上的損失。對結果進行討論,發現能解釋數據的最好的 K 值。二、算法原理
首先確定k,隨機選擇k個初始點之后所有點根據距離質點的距離進行聚類分析,離某一個質點a相較于其他質點最近的點分配到a的類中,根據每一類mean值更新迭代聚類中心,在迭代完成后分別計算訓 練集和測試集的損失函數SSE_train、SSE_test,畫圖進行分析。

偽代碼如下:
num=10 #k的種類for k in range(1,num): 隨機選擇k個質點 for i in range(n): #迭代n次 根據點與質點間的距離對于X_train進行聚類 根據mean值迭代更新質點 計算SSE_train 計算SSE_test畫圖
算法流程圖:
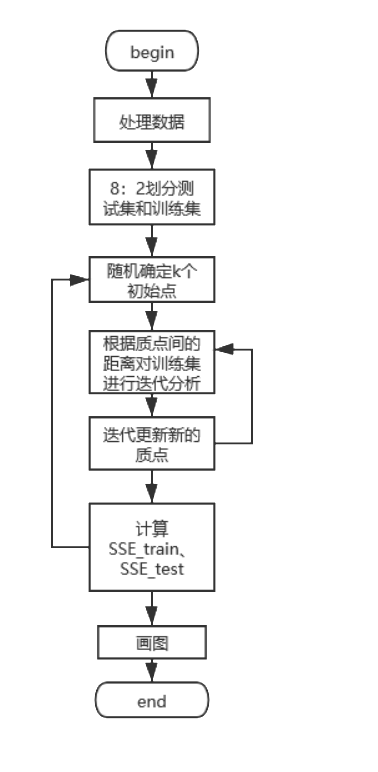
三、代碼實現
1、導入庫
import pandas as pdimport matplotlib.pyplot as pltimport numpy as npfrom sklearn.model_selection import train_test_split
2、計算距離
def distance(p1,p2): return np.sqrt((p1[0]-p2[0])**2+(p1[1]-p2[1])**2)
3、計算均值
def means(arr): return np.array([np.mean([p[0] for p in arr]),np.mean([p[1] for p in arr])])
4、二維數據處理
#數據處理data= pd.read_table(’cluster.dat’,sep=’t’,header=None) data.columns=[’x’]data[’y’]=Nonefor i in range(len(data)): #遍歷每一行 column = data[’x’][i].split( ) #分開第i行,x列的數據。split()默認是以空格等符號來分割,返回一個列表 data[’x’][i]=column[0] #分割形成的列表第一個數據給x列 data[’y’][i]=column[1] #分割形成的列表第二個數據給y列list=[]list1=[]for i in range(len(data)): list.append(float(data[’x’][i])) list.append(float(data[’y’][i])) list1.append(list) list=[]arr=np.array(list1)print(arr)

5、劃分數據集和訓練集
#按照8:2劃分數據集和訓練集X_train, X_test = train_test_split(arr,test_size=0.2,random_state=1)
6、主要聚類實現
count=10 #k的種類:1、2、3...10SSE_train=[] #訓練集的SSESSE_test=[] #測試集的SSEn=20 #迭代次數for k in range(1,count): cla_arr=[] #聚類容器 centroid=[] #質點 for i in range(k): j=np.random.randint(0,len(X_train)) centroid.append(list1[j]) cla_arr.append([]) centroids=np.array(centroid) cla_tmp=cla_arr #臨時訓練集聚類容器 cla_tmp1=cla_arr #臨時測試集聚類容器 for i in range(n): #開始迭代 for e in X_train: #對于訓練集中的點進行聚類分析 pi=0 min_d=distance(e,centroids[pi]) for j in range(k): if(distance(e,centroids[j])<min_d): min_d=distance(e,centroids[j]) pi=j cla_tmp[pi].append(e) #添加點到相應的聚類容器中 for m in range(k): if(n-1==i): break centroids[m]=means(cla_tmp[m])#迭代更新聚類中心 cla_tmp[m]=[] dis=0 for i in range(k): #計算訓練集的SSE_train for j in range(len(cla_tmp[i])): dis+=distance(centroids[i],cla_tmp[i][j]) SSE_train.append(dis) col = [’HotPink’,’Aqua’,’Chartreuse’,’yellow’,’red’,’blue’,’green’,’grey’,’orange’] #畫出對應K的散點圖 for i in range(k): plt.scatter([e[0] for e in cla_tmp[i]],[e[1] for e in cla_tmp[i]],color=col[i]) plt.scatter(centroids[i][0],centroids[i][1],linewidth=3,s=300,marker=’+’,color=’black’) plt.show() for e in X_test: #測試集根據訓練集的質點進行聚類分析 ki=0 min_d=distance(e,centroids[ki]) for j in range(k): if(distance(e,centroids[j])<min_d): min_d=distance(e,centroids[j]) ki=j cla_tmp1[ki].append(e) for i in range(k): #計算測試集的SSE_test for j in range(len(cla_tmp1[i])): dis+=distance(centroids[i],cla_tmp1[i][j]) SSE_test.append(dis)
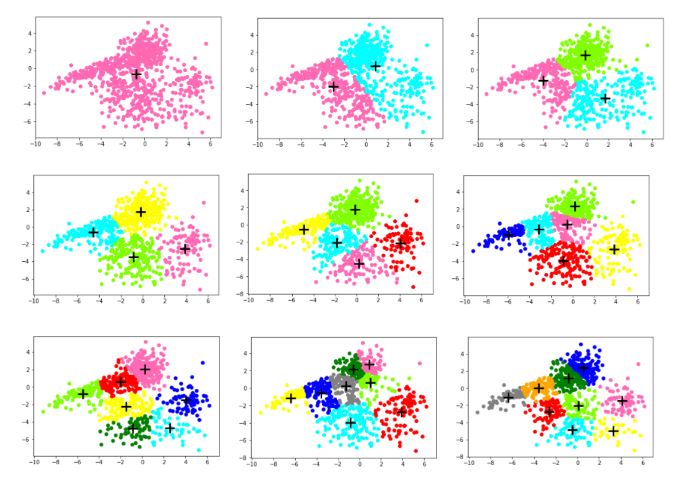
7、畫圖
SSE=[] #計算測試集與訓練集SSE的差值for i in range(len(SSE_test)): SSE.append(SSE_test[i]-SSE_train[i])x=[1,2,3,4,5,6,7,8,9]plt.figure()plt.plot(x,SSE_train,marker=’*’)plt.xlabel('K')plt.ylabel('SSE_train')plt.show() #畫出SSE_train的圖plt.figure()plt.plot(x,SSE_test,marker=’*’)plt.xlabel('K')plt.ylabel('SSE_test')plt.show() #畫出SSE_test的圖plt.figure()plt.plot(x,SSE,marker=’+’)plt.xlabel('K')plt.ylabel('SSE_test-SSE_train')plt.show() #畫出SSE_test-SSE_train的圖

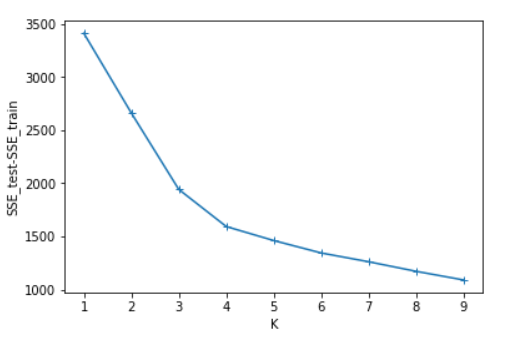
四、實驗結果分析
可以看出SSE隨著K的增長而減小,測試集和訓練集的圖形趨勢幾乎一致,在相同的K值下,測試集的SSE大于訓練集的SSE。于是我對于在相同的K值下的SSE_test和SSE_train做了減法(上圖3),可知K=4時數據得出結果最好。這里我主要使用肘部原則來判斷。本篇并未實現輪廓系數,參考文章:https://www.jb51.net/article/187771.htm
總結
到此這篇關于python 代碼實現k-means聚類分析(不使用現成聚類庫)的文章就介紹到這了,更多相關python k-means聚類分析內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備