詳解用Python爬蟲獲取百度企業(yè)信用中企業(yè)基本信息
一、背景
希望根據(jù)企業(yè)名稱查詢其經(jīng)緯度,所在的省份、城市等信息。直接將企業(yè)名稱傳給百度地圖提供的API,得到的經(jīng)緯度是非常不準確的,因此希望獲取企業(yè)完整的地理位置,這樣傳給API后結(jié)果會更加準確。百度企業(yè)信用提供了企業(yè)基本信息查詢的功能。希望通過Python爬蟲獲取企業(yè)基本信息。目前已基本實現(xiàn)了這一需求。本文最后會提供具體的代碼。代碼僅供學習參考,希望不要惡意爬取數(shù)據(jù)!
二、分析
以蘇寧為例。輸入“江蘇蘇寧”后,查詢結(jié)果如下:
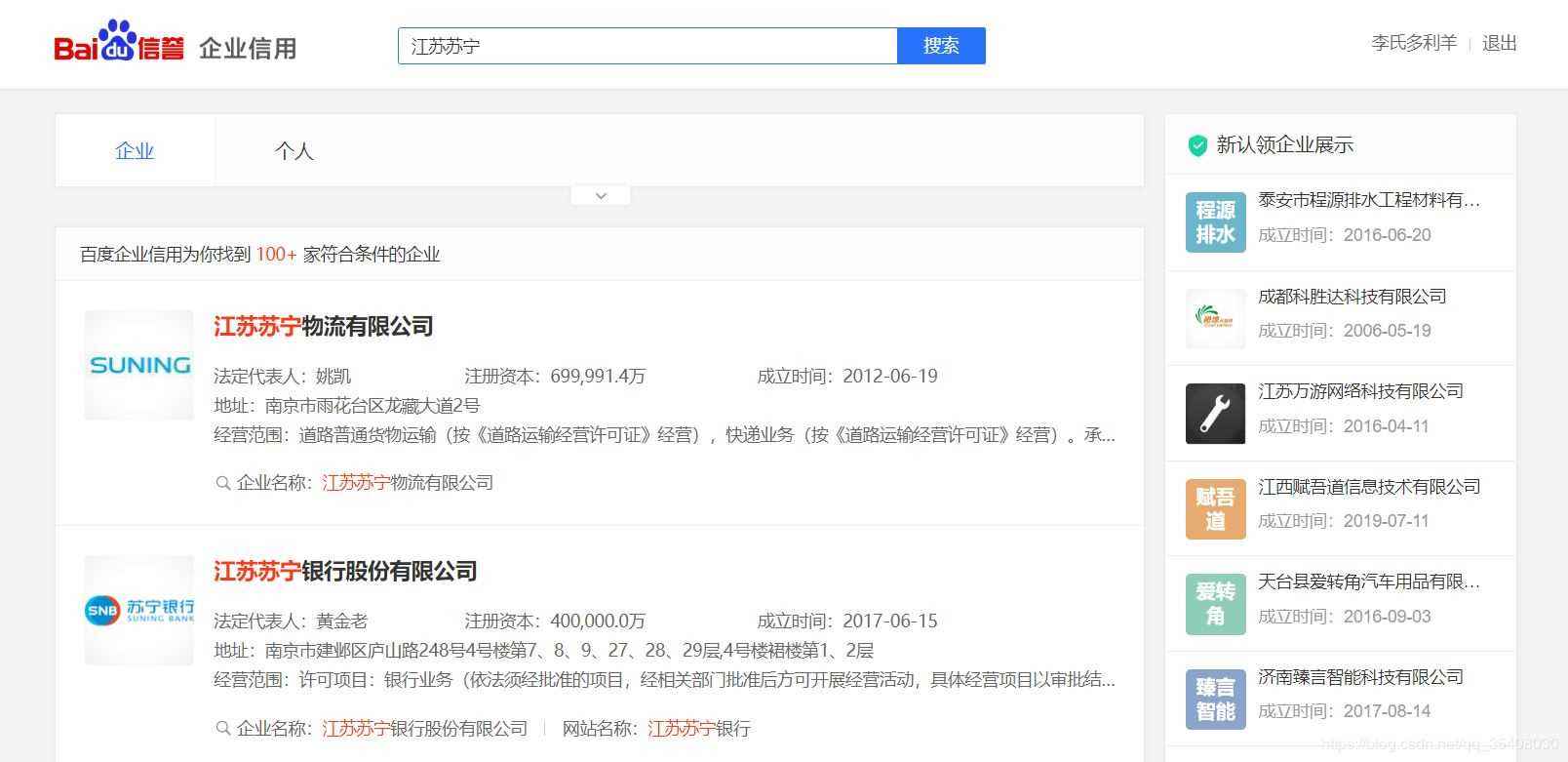
經(jīng)過分析,這里列示的企業(yè)信息是用JavaScript動態(tài)生成的。服務器最初傳過來的未經(jīng)渲染的HTML如下:
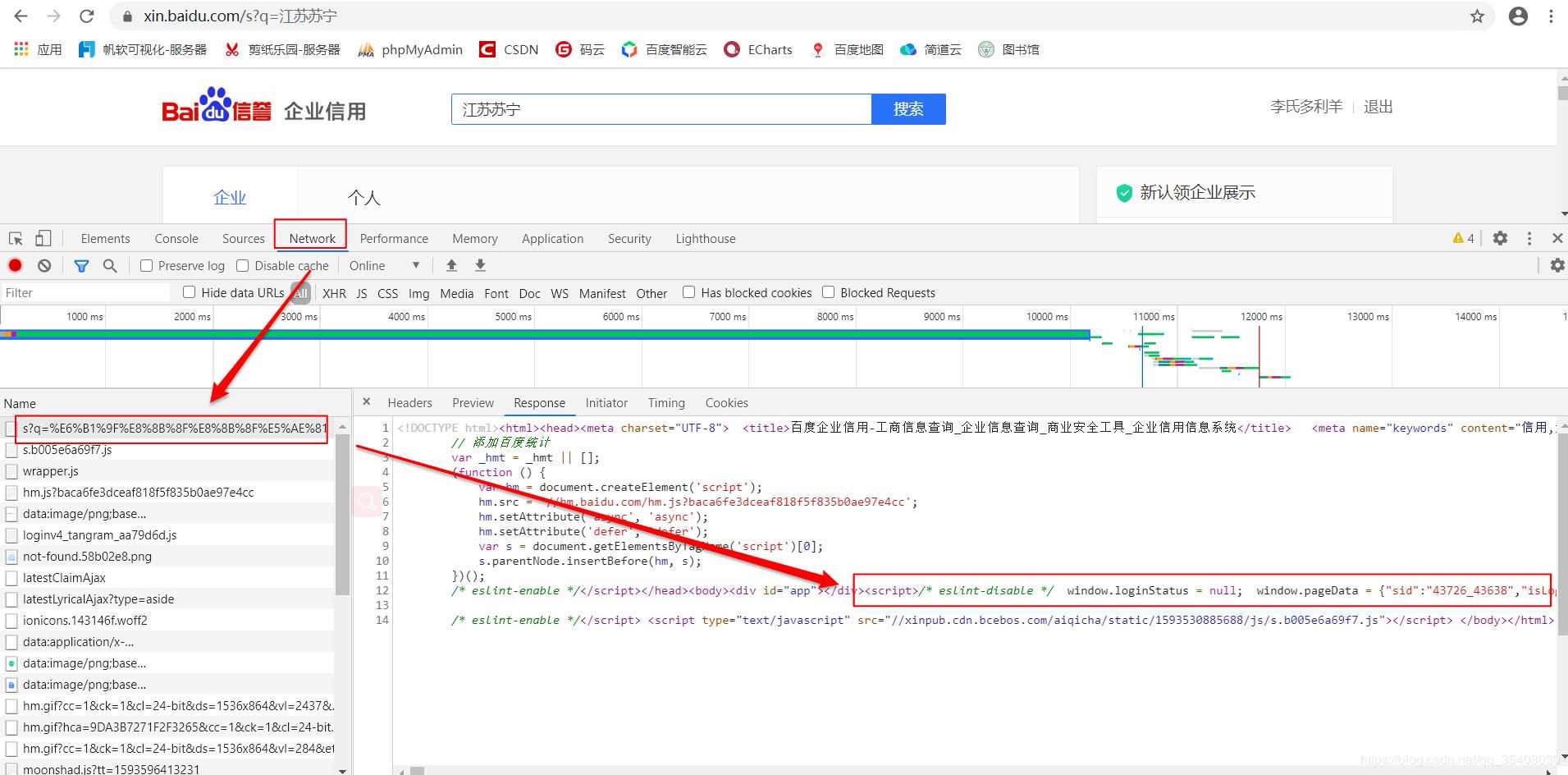
注意其中標注出來的JS代碼。有意思的是,企業(yè)基本信息都可以直接從這段JS代碼中獲取,無需構(gòu)造復雜的參數(shù)。

這是進一步查看的結(jié)果,注意那個“resultList”,后面存放的就是頁面中的企業(yè)信息。顯然,利用正則表達式提取需要的字符串,轉(zhuǎn)換成JSON就可以了。
三、源碼
以下代碼為查詢某個企業(yè)的基本信息提供了API:
#!/usr/bin/env python# -*- coding:utf-8 -*-# @Author: Wild Orange# @Email: jixuanfan_seu@163.com# @Date: 2020-06-19 22:38:14# @Last Modified time: 2020-07-01 17:33:13import requestsimport reimport jsonheaders={’User-Agent’: ’Chrome/76.0.3809.132’}#正則表達式提取數(shù)據(jù)re_get_js=re.compile(r’<script>([sS]*?)</script>’)re_resultList=re.compile(r’'resultList':([{.+?}]}])’)def Get_company_info(name):’’’@func: 通過百度企業(yè)信用查詢企業(yè)基本信息’’’url=’https://xin.baidu.com/s?q=%s’%nameres=requests.get(url,headers=headers)if res.status_code==200:html=res.textretVal=_parse_baidu_company_info(html)return retValelse:print(’無法獲取%s的企業(yè)信息’%name)def _parse_baidu_company_info(html):’’’@function:解析百度企業(yè)信用提供的企業(yè)基本信息@output: list of dict, [{},{},...]pid: 跳轉(zhuǎn)到具體企業(yè)頁面的參數(shù)bid: 具體企業(yè)頁面URL中的參數(shù)name: 企業(yè)名稱type: 企業(yè)類型date: 成立日期address: 地址person: 法人代表status: 存續(xù)狀態(tài)regCap: 注冊資本scope: 經(jīng)營范圍’’’js=re_get_js.findall(html)[1]data=re_resultList.search(js)if not data:returncompant_list=json.loads(data.group(1))retVal=[]for x in compant_list:regCap=x[’regCap’].replace(’,’,’’)if regCap[-1]==’萬’:regCap=regCap[:-1]regCap=float(regCap)address=x[’domicile’].replace(’<em>’,’’).replace(’</em>’,’’)temp_v={’pid’:x[’pid’],’bid’:x[’bid’],’name’:x[’titleName’],’type’:x[’entType’],’date’:x[’validityFrom’],’address’:address,’person’:x[’legalPerson’],’status’:x[’openStatus’],’regCap’:regCap,’scope’:x[’scope’]}retVal.append(temp_v)return retVal
四、使用方法
直接將需要查詢的企業(yè)名稱傳入Get_company_info:
res=Get_company_info(’江蘇蘇寧’)print(res)
結(jié)果:

需要注意的是:
返回的是字典構(gòu)成的數(shù)組,每個字典元素代表一家企業(yè)的信息。順序與瀏覽器中顯示的順序相同。字典中參數(shù)的含義已在_parse_baidu_company_info函數(shù)的注釋中說明。程序僅獲取第一頁的信息。如果要查詢多頁,可以修改源碼。程序僅獲取企業(yè)的基本信息,沒有進入企業(yè)的具體頁面,如:蘇寧物流具體頁面。不過返回結(jié)果中的pid或bid應該能用于構(gòu)造查詢頁面的URL。
最后再次強調(diào):代碼僅供學習參考,希望不要惡意爬取數(shù)據(jù)!
到此這篇關于詳解用Python爬蟲獲取百度企業(yè)信用中企業(yè)基本信息的文章就介紹到這了,更多相關Python爬蟲獲取百度企業(yè)信用內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持好吧啦網(wǎng)!
相關文章:
1. jQuery加PHP實現(xiàn)圖片上傳并提交的示例代碼2. Idea 2020.2安裝MyBatis Log Plugin 不可用的解決方法3. IDEA怎么切換Git分支的實現(xiàn)方法4. 解決idea刪除模塊后重新創(chuàng)建顯示該模塊已經(jīng)被注冊的問題5. 完美實現(xiàn)浮動元素橫排居中顯示6. JSP Tag Library-AjaxTags 1.0, released7. 小區(qū)后臺管理系統(tǒng)項目前端html頁面模板實現(xiàn)示例8. Python使用ElementTree美化XML格式的操作9. jsp request.getParameter() 和request.getAttribute()方法區(qū)別詳解10. JSP動態(tài)網(wǎng)頁開發(fā)技術(shù)概述

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備