Python中實現一行拆多行和多行并一行的示例代碼
粉絲提問
今天粉絲提了下面這樣一個問題,其中一個是'一行拆多行',另外一個是'多行并一行',貌似群友用power query已經解決了。但是基于Python怎么做呢?接著往下看。
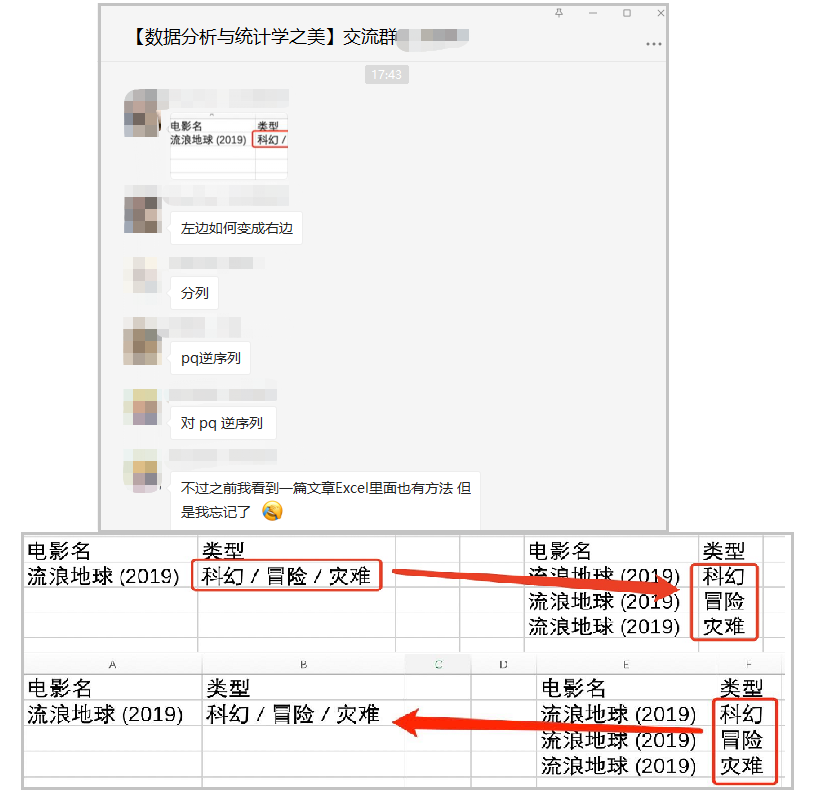
一行拆多行
上面這個問題我會提供兩個思路,供大家選擇,當然肯定是越簡單得越好。每一種方法中都有一些好用的技巧,希望大家能夠好好學習。
1)方法一
下方代碼中有很多重要的知識點,需要我們下去好好學習一下,我這里只提供解體思路,關于每個知識點怎么用,希望大家下去自行研究學習。
Pandas.melt()函數的用法; Series.str.split('/',expand=True)中,expand=True參數的用法; Series.sort_values()對文本進行排序; Python中enumerate()函數的用法;import pandas as pd# 讀取數據df = pd.read_excel('test1.xlsx',sheet_name='Sheet1')# 將一列炸裂成多列df[['類型1','類型2','類型3']] = df['電影類型'].str.split('/',expand=True)# 選取想要的列df_final = df[['電影名','類型1','類型2','類型3']]# 將行專列df_final = df_final.melt(id_vars=['電影名'],value_name='類型')# 對“電影名”字段進行排序df_final = df_final[['電影名','類型']]df_final.sort_values(by='電影名',inplace=True)# 刪除“類型==None”的行for index,value in enumerate(df_final['類型']): if value == None: df_final.drop(df_final.index[index],inplace=True)df_final
結果如下:

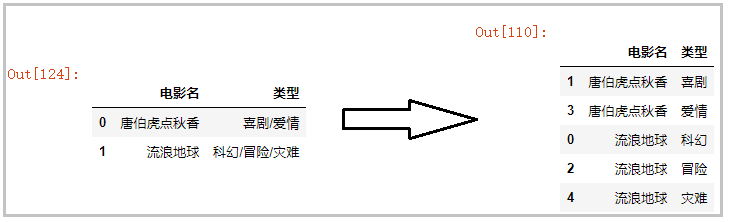
2)方法二
上述方法確實感覺復雜了,但是沒辦法,我之前的Pandas版本只有0.23.4,因此無法用explode()方法,進行炸裂操作。在pandas0.25版本的時候, DataFrame中才新增了一個explode方法, 專門用來將一行變多行。
Pandas.explode()函數的用法;
import pandas as pd# 讀取數據df = pd.read_excel('test1.xlsx',sheet_name='Sheet1')# 將一行拆分成列表形式,注意:這里不需要使用expand=True參數df['type'] = df['電影類型'].str.split('/')# 直接炸裂指定列df.explode('type')
結果如下:
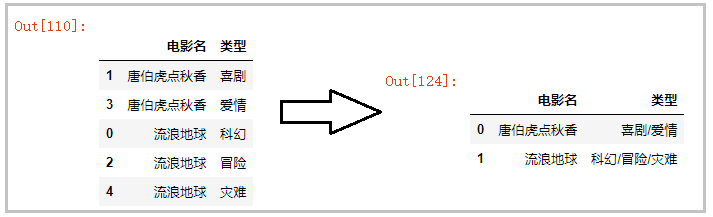
多行并一行
這里沒有使用什么特別的知識,好好理解Pandas中分組聚合應用某個函數,即可輕松解決這個問題。
import pandas as pd# 讀取數據df = pd.read_excel('test1.xlsx',sheet_name='Sheet2')# 分組聚合,應用某個函數def func(df): return ’,’.join(df.values)df = df.groupby(by=’電影名’).agg(func).reset_index()df
結果如下:
到此這篇關于Python中實現一行拆多行和多行并一行的示例代碼的文章就介紹到這了,更多相關Python 一行拆多行和多行并一行內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備