Python爬蟲進階之爬取某視頻并下載的實現
這幾天在家閑得無聊,意外的挖掘到了一個資源網站(你懂得),但是網速慢廣告多下載不了種種原因讓我突然萌生了爬蟲的想法。
下面說說流程:
一、網站分析
首先進入網站,F12檢查,本來以為這種低端網站很好爬取,是我太低估了web主。可以看到我刷新網頁之后,出現了很多js文件,并且響應獲取的代碼與源代碼不一樣,這就不難猜到這個網站是動態加載頁面。

目前我知道的動態網頁爬取的方法只有這兩種:1、從網頁響應中找到JS腳本返回的JSON數據;2、使用Selenium對網頁進行模擬訪問。源代碼問題好解決,重要的是我獲取的源代碼中有沒有我需要的東西。我再一次進入網站進行F12檢查源代碼,點擊左上角然后在頁面點擊一個視頻獲取一個元素的代碼,結果里面沒有嵌入的原視頻鏈接(看來我真的是把別人想的太笨了)。
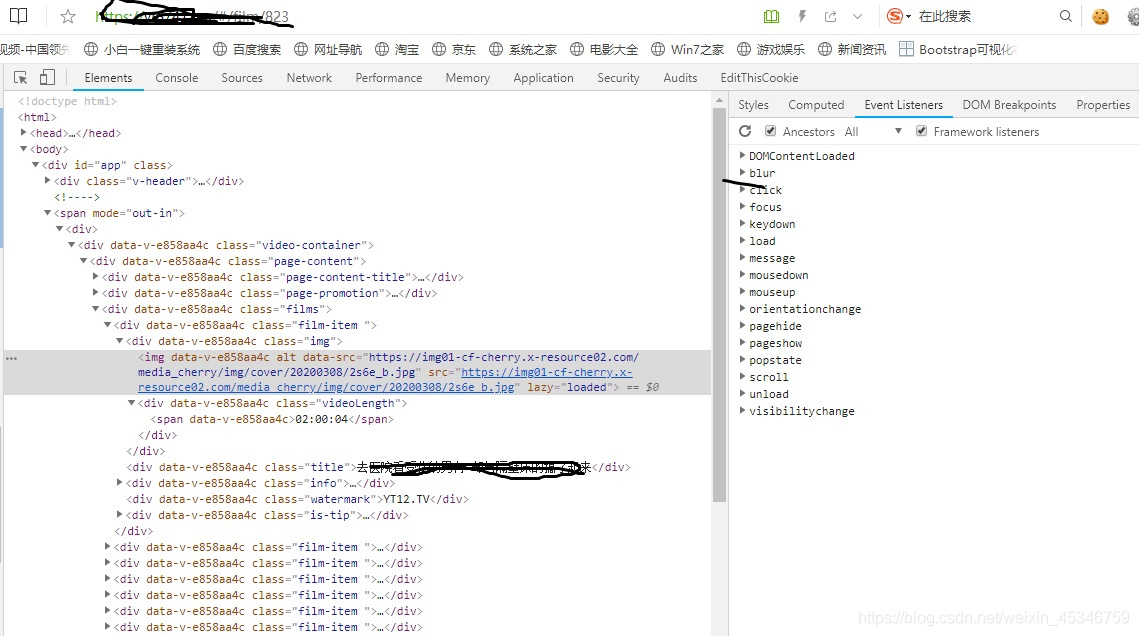
沒辦法只有進行抓包,去找js請求的接口。再一次F12打開網頁調試工具,點擊單獨的一個視頻進行播放,然后在Network中篩選一下,只看HXR響應(HXR全稱是XMLHTTPRequest,HMLHTTP是AJAX網頁開發技術的重要組成部分。除XML之外,XMLHTTP還能用于獲取其它格式的數據,如JSON或者甚至純文本。)。
然后我一項一項的去檢查返回的響應信息,發現當我點擊播放的時候有后綴為.m3u8的鏈接,隨后就不斷刷新.ts文件的鏈接。

本來以為這就是原視頻的地址,我傻傻的直接從這個m3u8文件的headers中的URL直接進入網站看看,結果傻眼了,獲取的是一串串.ts的文件名。
沒辦法只能百度君了。 科普了一下,也就說我們必須把ts文件都下載下來進行合并之后才能轉成視頻。

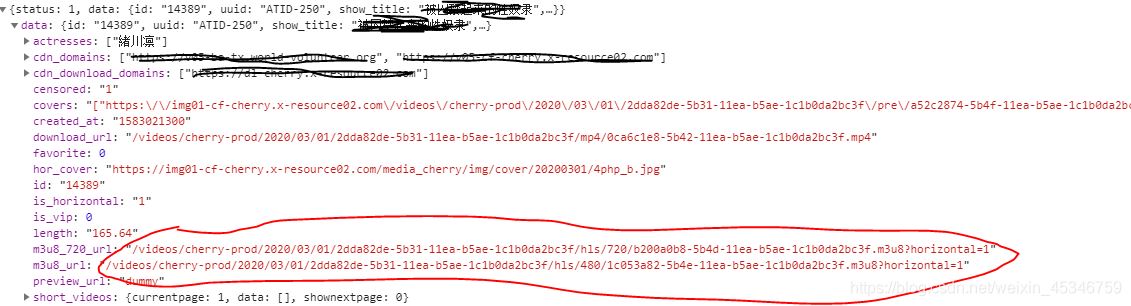
好了,視頻原地址弄清楚了,現在我們開始從一個視頻擴展到首頁的整個頁面的視頻。再一次進行抓包分析,發現一個API中包含了首頁的分類列表,然而里面并沒有進入分類的URL地址,只有一個tagid值和圖片的地址。
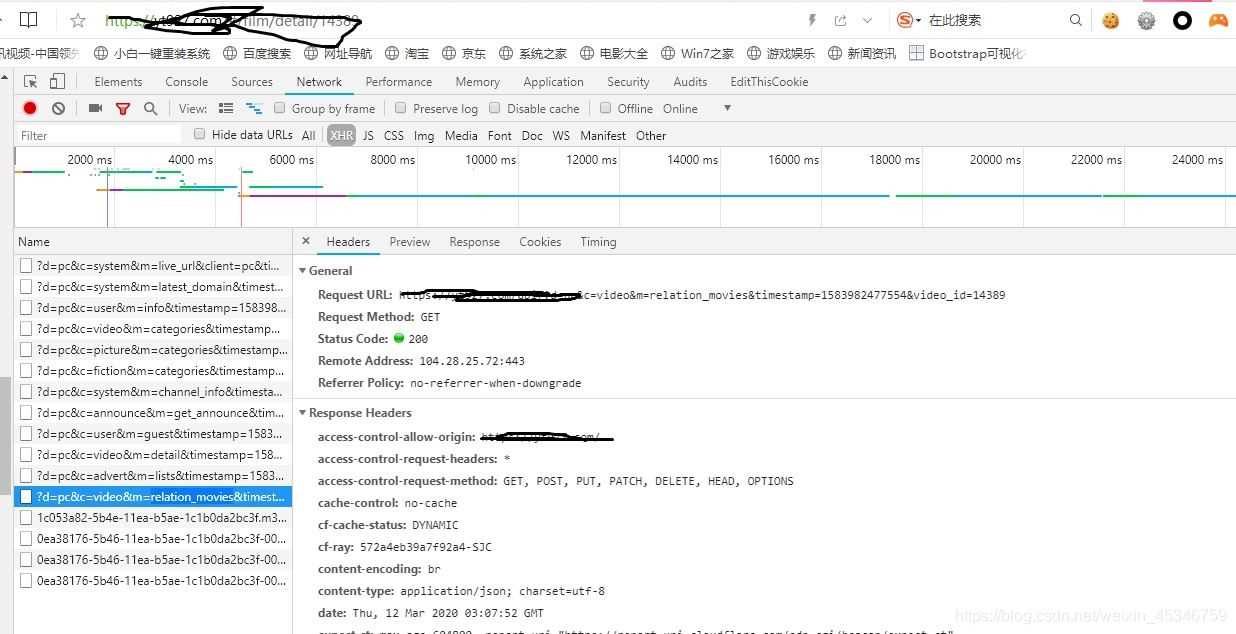
于是我又在主頁點一個分類,再次進行抓包,發現了一個API中包含了一個分類的單頁所有視頻的信息,通過他們的headers中的URL對比發現,關于視頻的前一部分都是https:xxxxxxx&c=video,然后m=categories,通過字面意思我們都可以知道是分類,而每個tagid值對應不同的分類。并且還發現每個URL中都追加了時間戳timestamp(這是web主為了確保請求不會在它第一次被發送后即緩存,看來還是有小心機啊)。當m=lists,則是每個分類下的視頻列表,這里面我們就可以找到每個視頻對應的ID了。

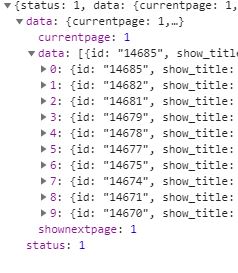
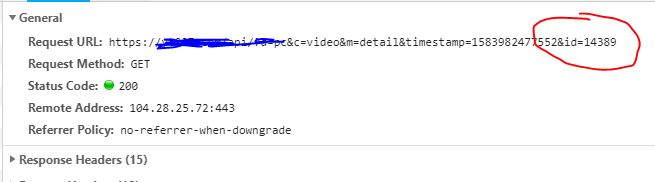
通過id我們可以獲取到視頻的詳細信息,并且還有m3u8文件URL地址的后面一部分。
好了,網站我們解析清楚了,現在開始堆碼了。
二、寫代碼
導入相關模塊
import requestsfrom datetime import datetimeimport re#import json import timeimport os#視頻分類和視頻列表URL的前一段url = 'http://xxxxxxx/api/?d=pc&c=video&'#m3u8文件和ts文件的URL前一段m3u8_url =’https://xxxxxxxxxxxxx/videos/cherry-prod/2020/03/01/2dda82de-5b31-11ea-b5ae-1c1b0da2bc3f/hls/480/’#構造請求頭信息header = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2'}#創建空列表存放視頻信息vediomassag=’’#返回當前時間戳TimeStamp = int(datetime.timestamp(datetime.now()))
2.定義函數,獲取網站首頁分類列表信息
#自定義函數獲取分類def get_vediocategory(url, TimeStamp): cgURL = url + 'm=categories×tamp=' + str(TimeStamp) + ’&’ response = requests.get(cgURL, headers=header) category = response.text# strrr=’'%s'’%category# return strrr return category
3.定義函數,通過上一個函數返回的分類信息,根據分類對應的id,輸入id并傳輸到當前URL中以便獲取分類下的視頻列表信息
#獲取分類后的視頻列表def get_vedioList(url, TimeStamp, tagID): listURL = url + 'm=lists×tamp=' + str(TimeStamp) + ’&’ + 'page=1&tag_id=' + str(tagID) + '&sort_type=&is_vip=0' response = requests.get(listURL, headers=header) vedioLists = response.text return vedioLists
4.在視頻列表信息中獲取視頻對應的id,獲取單個視頻詳細信息的URL
#獲取單個視頻的詳細信息def get_vediomassages(url, TimeStamp, vedioID): videoURL = url + 'm=detail×tamp=' + str(TimeStamp) + ’&’ + '&id=' + str(vedioID) response = requests.get(videoURL, headers=header) vediomassag = response.text return vediomassag
5.在視頻詳細信息中找到m3u8文件的下載地址,并將文件保存到創建的文件中
#將下載的m3u8文件放進創建的ts列表文件中def get_m3u8List(m3u8_url,vediomassag): lasturl = r’'m3u8_720_url':'(.*?)','download_url’ last_url =re.findall(lasturl,vediomassag) lastURL=m3u8_url+str(last_url) response = requests.get(lastURL, headers=header) tsList = response.text cur_path=’E:files’ #在指定路徑建立文件夾 try: if not os.path.isdir(cur_path): #確認文件夾是否存在 os.makedirs(cur_path) #不存在則新建 except: print('文件夾存在') filename=cur_path+’t2.txt’ #在文件夾中存放txt文件 f = open(filename,’a’, encoding='utf-8') f.write(tsList) f.close print(’創建%s文件成功’%(filename)) return filename
6.將m3u8文件中的ts單個提取出來放進列表中。
# 提取ts列表文件的內容,逐個拼接ts的url,形成listdef get_tsList(filename): ls = [] with open(filename, 'r') as file: line = f.readlines() for line in lines: if line.endswith('.tsn'): ls.append(line[:-1]) return ls
7.遍歷列表獲取單個ts地址,請求下載ts文件放進創建的文件夾中
# 批量下載ts文件def DownloadTs(ls): length = len(ls) root=’E:mp4’ try: if not os.path.exists(root): os.mkdir(root) except: print('文件夾創建失敗') try: for i in range(length): tsname = ls[i][:-3] ts_URL=url+ls[i] print(ts_URL) r = requests.get(ts_URL) with open(root, ’a’) as f: f.write(r.content) f.close() print(’r’ + tsname + ' -->OK ({}/{}){:.2f}%'.format(i, length, i * 100 / length), end=’’) print('下載完畢') except: print('下載失敗')
代碼整合
import requestsfrom datetime import datetimeimport re#import jsonimport timeimport osurl = 'http://xxxxxxxx/api/?d=pc&c=video&'m3u8_url =’https://xxxxxxxxxxxxxxx/videos/cherry-prod/2020/03/01/2dda82de-5b31-11ea-b5ae-1c1b0da2bc3f/hls/480/’header = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2'}vediomassag=’’TimeStamp = int(datetime.timestamp(datetime.now()))#自定義函數獲取分類def get_vediocategory(url, TimeStamp): cgURL = url + 'm=categories×tamp=' + str(TimeStamp) + ’&’ response = requests.get(cgURL, headers=header) category = response.text# strrr=’'%s'’%category# return strrr return category#獲取分類后的視頻列表def get_vedioList(url, TimeStamp, tagID): listURL = url + 'm=lists×tamp=' + str(TimeStamp) + ’&’ + 'page=1&tag_id=' + str(tagID) + '&sort_type=&is_vip=0' response = requests.get(listURL, headers=header) vedioLists = response.text return vedioLists#獲取單個視頻的詳細信息def get_vediomassages(url, TimeStamp, vedioID): videoURL = url + 'm=detail×tamp=' + str(TimeStamp) + ’&’ + '&id=' + str(vedioID) response = requests.get(videoURL, headers=header) vediomassag = response.text return vediomassag#將下載的m3u8文件放進創建的ts列表文件中def get_m3u8List(m3u8_url,vediomassag): lasturl = r’'m3u8_720_url':'(.*?)','download_url’ last_url =re.findall(lasturl,vediomassag) lastURL=m3u8_url+str(last_url) response = requests.get(lastURL, headers=header) tsList = response.text cur_path=’E:files’ #在指定路徑建立文件夾 try: if not os.path.isdir(cur_path): #確認文件夾是否存在 os.makedirs(cur_path) #不存在則新建 except: print('文件夾存在') filename=cur_path+’t2.txt’ #在文件夾中存放txt文件 f = open(filename,’a’, encoding='utf-8') f.write(tsList) f.close print(’創建%s文件成功’%(filename)) return filename# 提取ts列表文件的內容,逐個拼接ts的url,形成listdef get_tsList(filename): ls = [] with open(filename, 'r') as file: line = f.readlines() for line in lines: if line.endswith('.tsn'): ls.append(line[:-1]) return ls# 批量下載ts文件def DownloadTs(ls): length = len(ls) root=’E:mp4’ try: if not os.path.exists(root): os.mkdir(root) except: print('文件夾創建失敗') try: for i in range(length): tsname = ls[i][:-3] ts_URL=url+ls[i] print(ts_URL) r = requests.get(ts_URL) with open(root, ’a’) as f: f.write(r.content) f.close() print(’r’ + tsname + ' -->OK ({}/{}){:.2f}%'.format(i, length, i * 100 / length), end=’’) print('下載完畢') except: print('下載失敗')’’’# 整合所有ts文件,保存為mp4格式(此處函數復制而來未做實驗,本人直接在根目錄命令行輸入copy/b*.ts 文件名.mp4,意思是將所有ts文件合并轉換成自己命名的MP4格式文件。)def MergeMp4(): print('開始合并') path = 'E://mp4//' outdir = 'output' os.chdir(root) if not os.path.exists(outdir): os.mkdir(outdir) os.system('copy /b *.ts new.mp4') os.system('move new.mp4 {}'.format(outdir)) print('結束合并')’’’ if __name__ == ’__main__’:# 將獲取的分類信息解碼顯示出來# print(json.loads(get_vediocategory(url, TimeStamp))) print(get_vediocategory(url, TimeStamp)) tagID = input('請輸入分類對應的id') print(get_vedioList(url, TimeStamp, tagID)) vedioID = input('請輸入視頻對應的id') get_vediomassages(url, TimeStamp, vedioID) get_m3u8List(m3u8_url,vediomassag) get_tsList(filename) DownloadTs(ls)# MergeMp4()
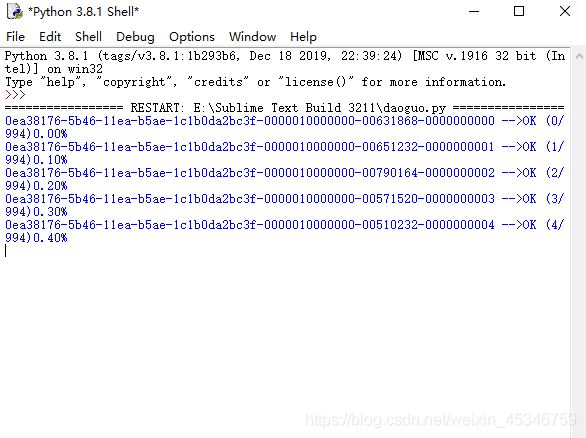
此時正在下載
三、問題:
首先對于這種網站采取的爬取方法有很多,而我的方法相對來說有點太低端了,并且我也 是第一次寫博客,第一次寫爬蟲這類程序,在格式上命名上存在著很多問題,函數的用法不全面。并且在運行的時候效率低速度太慢。在獲取分類列表和視頻列表時,因為是JSON文件,需要轉碼,過程太多加上程序不夠穩定我就注釋掉了。還有就是對于這種動態網頁了解不夠,所以學爬蟲的小伙伴一定要把網頁的基礎搞好。希望各位大佬多指正多批評,讓我們這些小白一起努力學好Python。
注意:里面所有的鏈接我的給打碼了,怕被和諧了哈哈
到此這篇關于Python爬蟲進階之爬取某視頻并下載的實現的文章就介紹到這了,更多相關Python 爬取某視頻并下載內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備