python實現(xiàn)selenium網(wǎng)絡(luò)爬蟲的方法小結(jié)
selenium最初是一個自動化測試工具,而爬蟲中使用它主要是為了解決requests無法直接執(zhí)行JavaScript代碼的問題,selenium本質(zhì)是通過驅(qū)動瀏覽器,完全模擬瀏覽器的操作,比如跳轉(zhuǎn)、輸入、點擊、下拉等,來拿到網(wǎng)頁渲染之后的結(jié)果,可支持多種瀏覽器,這里只用到谷歌瀏覽器。
1.selenium初始化方法一:會打開網(wǎng)頁# 該方法會打開goole網(wǎng)頁from selenium import webdriverurl = ’網(wǎng)址’driver = webdriver.Chrome()driver.get(url)driver.maximize_window() # 實現(xiàn)窗口最大化方法二:不會打開網(wǎng)頁
# 該方法會隱式打開goole網(wǎng)頁from selenium import webdriverurl = ’網(wǎng)址’driver = webdriver.ChromeOptions()driver.add_argument('headless')driver = webdriver.Chrome(options=driver)driver.get(url)
driver = webdriver.Chrome()出錯是因為沒有chromedriver.exe這個文件
2.元素定位
在selenium中,可以有多種方法對元素進行定位,個人通常喜歡用Xpath和selector來定位元素,這樣就不用一個一個的去找節(jié)點,直接在網(wǎng)頁上定位到元素復(fù)制就行。
driver.find_element_by_id() # 通過元素ID定位driver.find_element_by_name() # 通過元素Name定位driver.find_element_by_class_name() # 通過類名定位driver.find_element_by_tag_name() # 通過元素TagName定位driver.find_element_by_link_text() # 通過文本內(nèi)容定位driver.find_element_by_partial_link_text()driver.find_element_by_xpath() # 通過Xpath語法定位driver.find_element_by_css_selector() # 通過選擇器定位
注:若尋找多個元素,要記得用復(fù)數(shù)來選擇(element改為elements)
# 例如[i.text for i in driver.find_elements_by_xpath()]
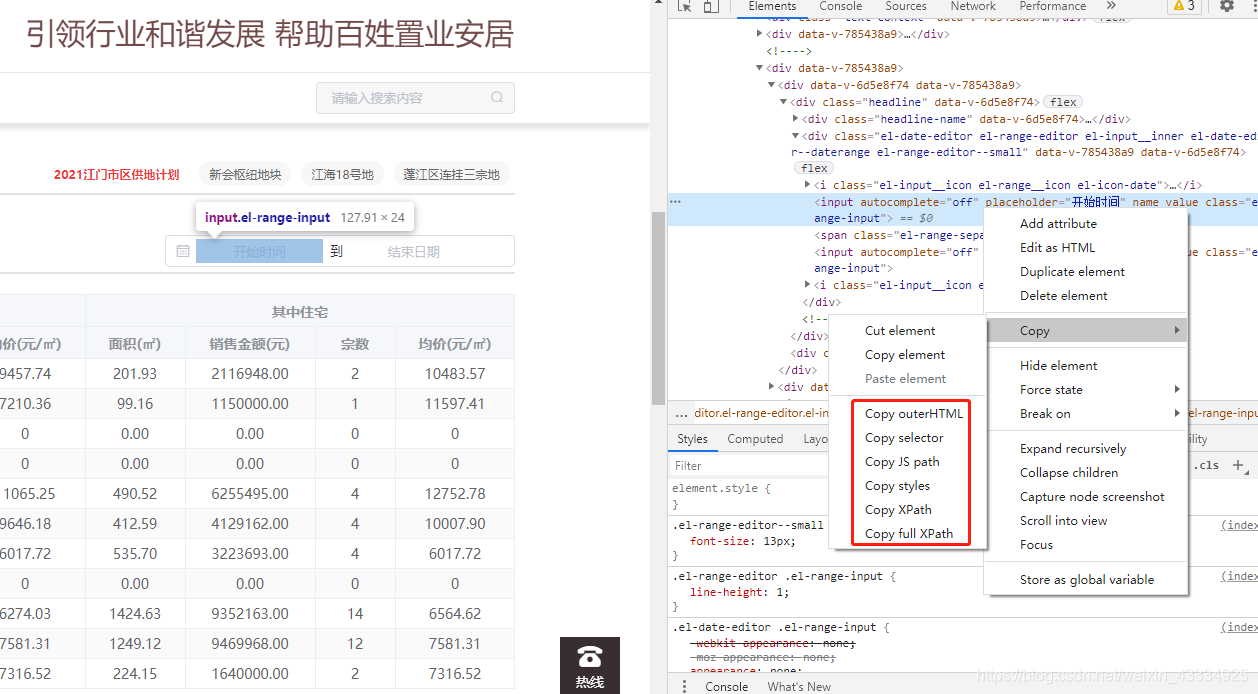
3.建立點擊事件
因為有些網(wǎng)站的需求,需建立點擊事件,如下圖的這種時間選擇,需要設(shè)置點擊和輸入內(nèi)容,設(shè)置的方法也很簡單。

driver.find_element_by_css_selector(’’).click() # 點擊driver.find_element_by_css_selector(’’).send_keys(’2021-3-9’) # 輸入內(nèi)容
4.切換窗口
有些網(wǎng)站點擊之后會產(chǎn)生新窗口,這時就需要進行窗口的切換才能進行元素定位
win = driver.window_handles # 獲取當前瀏覽器的所有窗口driver.switch_to.window(win[-1]) # 切換到最后打開的窗口driver.close() # 關(guān)閉當前窗口driver.switch_to.window(win[0]) # 切換到最初的窗口
5.iframe問題
有些網(wǎng)站會采用iframe來編寫頁面,這時就需要進入到iframe才可以獲取元素,一般有多少個iframe就需要進入多少個iframe。

# 有兩個iframe,需逐步進入iframe1 = driver.find_element_by_xpath(’’)driver.switch_to.frame(iframe1)iframe2 = driver.find_element_by_xpath(’’)driver.switch_to.frame(iframe2)
到此這篇關(guān)于python實現(xiàn)selenium網(wǎng)絡(luò)爬蟲的文章就介紹到這了,更多相關(guān)python selenium網(wǎng)絡(luò)爬蟲內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. ASP.NET MVC使用jQuery ui的progressbar實現(xiàn)進度條2. Ajax對xml信息的接收和處理操作實例分析3. Jsp中request的3個基礎(chǔ)實踐4. Ajax返回值類型與用法實例分析5. XML入門精解之結(jié)構(gòu)與語法6. el-table表格動態(tài)合并相同數(shù)據(jù)單元格(可指定列+自定義合并)7. vue3頁面跳轉(zhuǎn)的兩種方式8. uniapp 手機驗證碼輸入框?qū)崿F(xiàn)代碼(隨機數(shù)、倒計時、隱藏手機號碼中間四位)可以直接使用9. PHP開發(fā)技巧之PHAR反序列化詳解10. Rollup 簡易入門示例教程
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備