Python爬蟲進階之Beautiful Soup庫詳解
BeautifulSoup4 是一個 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 的數(shù)據(jù)。和 lxml 庫一樣。
lxml 只會局部遍歷,而 BeautifulSoup4 是基于 HTML DOM 的,會加載整個文檔,解析 整個 DOM 樹,因此內(nèi)存開銷比較大,性能比較低。
BeautifulSoup4 用來解析 HTML 比較簡單,API 使用非常人性化,支持 CSS 選擇器,是 Python 標(biāo)準(zhǔn)庫中的 HTML 解析器,也支持 lxml 解析器。
二、Beautiful Soup庫安裝目前,Beautiful Soup 的最新版本是 4.x 版本,之前的版本已經(jīng)停止開發(fā),這里推薦使用 pip 來安裝,安裝命令如下:
pip install beautifulsoup4
查看 Beautiful Soup 安裝是否成功
from bs4 import BeautifulSoup soup = BeautifulSoup(’<p>Hello</p>’,’html.parser’) print(soup.p.string)
注意:□ 這里雖然安裝的是 beautifulsoup4 這個包,但是引入的時候卻是 bs4,因為這個包源 代碼本身的庫文件名稱就是bs4,所以安裝完成后,這個庫文件就被移入到本機 Python3 的 lib 庫里,識別到的庫文件就叫作 bs4。□ 因此,包本身的名稱和我們使用時導(dǎo)入包名稱并不一定是一致的。
三、Beautiful Soup 庫解析器Beautiful Soup 在解析時實際上依賴解析器,它除了支持 Python 標(biāo)準(zhǔn)庫中的 HTML 解析器外,還支持一些第三方解析器(比如 lxml)。下表列出了 Beautiful Soup 支持的解析器。
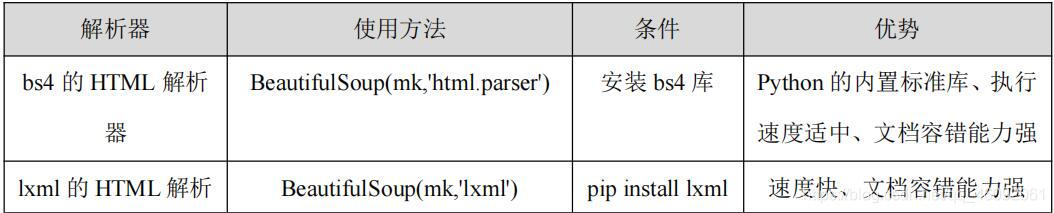

初始化 BeautifulSoup 使用 lxml,把第二個參數(shù)改為 lxml
from bs4 import BeautifulSoup bs = BeautifulSoup(’<p>Python</p>’,’lxml’) print(bs.p.string)四、Beautiful Soup庫基本用法

獲取 title 節(jié)點,查看它的類型
from bs4 import BeautifulSouphtml = ’’’ <html><head><title>The Dormouse’s story</title></head> <body> <p name='dromouse'><b>The Dormouse’s story</b></p> <p class='story'>Once upon a time there were three little sisters; and their names were <a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link1'><!-- Elsie --></a>, <a rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link2'>Lacie</a> and <a rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link3'>Tillie</a>; and they lived at the bottom of a well.</p> <p class='story'>...</p> </body> </html>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)print(soup.prettify())print(soup.title.string)
執(zhí)行結(jié)果如下所示:
The Dormouse’s story
上述示例首先聲明變量 html,它是一個 HTML 字符串。接著將它當(dāng)作第一個參數(shù)傳給 BeautifulSoup 對象,該對象的第二個參數(shù)為解析器的類型(這里使用 lxml),此時就完成了 BeaufulSoup 對象的初始化。 接著調(diào)用 soup 的各個方法和屬性解析這串 HTML 代碼了。 調(diào)用 prettify()方法。可以把要解析的字符串以標(biāo)準(zhǔn)的縮進格式輸出。這里需要注意的是, 輸出結(jié)果里面包含 body 和 html 節(jié)點,也就是說對于不標(biāo)準(zhǔn)的 HTML 字符串 BeautifulSoup, 可以自動更正格式。 調(diào)用 soup.title.string,輸出 HTML 中 title 節(jié)點的文本內(nèi)容。所以,soup.title 可以選出 HTML 中的 title 節(jié)點,再調(diào)用 string 屬性就可以得到里面的文本了。選擇元素
# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)# 獲取head標(biāo)簽print(soup.head)# 獲取p標(biāo)簽print(soup.p)
運行結(jié)果:
<head><title>The Dormouse’s story</title></head><p name='dromouse'><b>The Dormouse’s story</b></p>
從上述示例運行結(jié)果可以看到,獲取 head 節(jié)點的結(jié)果是節(jié)點加其內(nèi)部的所有內(nèi)容。 最后,選擇了 p 節(jié)點。不過這次情況比較特殊,我們發(fā)現(xiàn)結(jié)果是第一個 p 節(jié)點的內(nèi)容,后面的幾個 p 節(jié)點并沒有選到。也就是說,當(dāng)有多個節(jié)點時,這種選擇方式只會選擇到第一個匹配的節(jié)點,其他的后面節(jié)點都會忽略。調(diào)用 name 屬性獲取節(jié)點的名稱
# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)# 調(diào)用 name 屬性獲取節(jié)點的名稱print(soup.title.name)
運行結(jié)果:
title
調(diào)用 attrs 獲取所有屬性
# 調(diào)用 attrs 獲取所有屬性print(soup.p.attrs)print(soup.p.attrs[’name’])
運行結(jié)果:
{’class’: [’title’], ’name’: ’dromouse’}dromouse
從上述運行結(jié)果可以看到,attrs 的返回結(jié)果是字典形式,它把選擇節(jié)點的所有屬性和屬性值組合成一個字典。如果要獲取 name 屬性,就相當(dāng)于從字典中獲取某個鍵值,只需要用中括號加屬性名就可以了。例如,要獲取 name 屬性,就可以通過 attrs[‘name’] 來得到。
簡單獲取屬性的方式
print(soup.p[’name’])print(soup.p[’class’])
這里需要注意的是,獲取屬性有的返回結(jié)果是字符串,有的返回結(jié)果是字符串組成的列表。
比如,name 屬性的值是唯一的,返回的結(jié)果就是單個字符串。而對于 class,一個節(jié)點元素可能有多個 class,所以返回的是列表。
調(diào)用 string 屬性獲取節(jié)點元素包含的文本內(nèi)容
print(’調(diào)用 string 屬性獲取節(jié)點元素包含的文本內(nèi)容’)print(soup.p.string)
嵌套選擇
print(’嵌套選擇’)print(soup.head.title)# 獲取title的類型print(type(soup.head.title))# 獲取標(biāo)簽內(nèi)容print(soup.head.title.string)
運行結(jié)果:
<title>The Dormouse’s story</title><class ’bs4.element.Tag’>The Dormouse’s story
從上述示例運行結(jié)果可以看到,調(diào)用 head 之后再次調(diào)用 title 可以選擇 title 節(jié)點元素。 輸出了它的類型可以看到,它仍然是 bs4.element.Tag 類型。也就是說,我們在 Tag 類型的基礎(chǔ)上再次選擇得到的依然還是 Tag 類型,每次返回的結(jié)果都相同。
調(diào)用 children 屬性,獲取它的直接子節(jié)點
from bs4 import BeautifulSouphtml = ’’’ <html> <head> <title>The Dormouse’s story</title> </head> <body> <p class='story'> Once upon a time there were three little sisters; and their names were <a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link1'> <span>Elsie</span> </a> <a rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link2'>Lacie</a> and <a rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link3'>Tillie</a> and they lived at the bottom of a well. </p> <p class='story'>...</p>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)# 獲取孩子結(jié)點print(soup.p.children)# 遍歷孩子結(jié)點# 將列表中元素與下標(biāo)枚舉為元組# 獲取p標(biāo)簽下的孩子標(biāo)簽for i, child in enumerate(soup.p.children): print(i, child)
執(zhí)行結(jié)果:
<list_iterator object at 0x0CACF448>0 Once upon a time there were three little sisters; and their names were 1 <a id='link1'><span>Elsie</span></a>2 3 <a id='link2'>Lacie</a>4 and 5 <a id='link3'>Tillie</a>6 and they lived at the bottom of a well.
從上述示例運行結(jié)果可以看到,調(diào)用 children 屬性,返回結(jié)果是生成器類型。用 for 循環(huán)輸出相應(yīng)的內(nèi)容。
調(diào)用 parent 屬性,獲取某個節(jié)點元素的父節(jié)點
from bs4 import BeautifulSouphtml = ’’’ <html> <head> <title>The Dormouse’s story</title> </head> <body><p class='story'> Once upon a time there were three little sisters; and their names were <a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link1'> <span>Elsie</span> </a> </p> <p class='story'>...</p>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)# 獲取父結(jié)點print(soup.a.parent)
運行結(jié)果:
<p class='story'> Once upon a time there were three little sisters; and their names were <a id='link1'><span>Elsie</span></a></p>
從上述示例運行結(jié)果可以看到,我們選擇的是第一個 a 節(jié)點的父節(jié)點元素,它的父節(jié)點 是 p 節(jié)點,輸出結(jié)果便是 p 節(jié)點及其內(nèi)部的內(nèi)容。 需要注意的是,這里輸出的僅僅是 a 節(jié)點的直接父節(jié)點,而沒有再向外尋找父節(jié)點的祖 先節(jié)點。如果想獲取所有的祖先節(jié)點,可以調(diào)用 parents 屬性。
調(diào)用 parents 屬性,獲取某個節(jié)點元素的祖先節(jié)點
from bs4 import BeautifulSouphtml = ’’’ <html> <body><p class='story'> <a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link1'> <span>Elsie</span> </a> </p>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)# 獲取父結(jié)點print(type(soup.a.parents)) # 獲取類型print(list(enumerate(soup.a.parents)))
運行結(jié)果:
[(0, <p class='story'><a id='link1'><span>Elsie</span></a></p>), (1, <body><p class='story'><a id='link1'><span>Elsie</span></a></p></body>), (2, <html><body><p class='story'><a id='link1'><span>Elsie</span></a></p></body></html>), (3, <html><body><p class='story'><a id='link1'><span>Elsie</span></a></p></body></html>)]
調(diào)用 next_sibling 和 previous_sibling 分別獲取節(jié)點的下一個和上一個兄弟元素
from bs4 import BeautifulSouphtml = ’’’ <html> <body> <p class='story'> Once upon a time there were three little sisters; and their names were <a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link1'> <span>Elsie</span> </a> Hello <a rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link2'>Lacie</a> and <a rel='external nofollow' rel='external nofollow' rel='external nofollow' id='link3'>Tillie</a> and they lived at the bottom of a well. </p>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)# 獲取下一個結(jié)點的屬性print(’Next Sibling’, soup.a.next_sibling)print(’Previous Sibling’, soup.a.previous_sibling)
運行結(jié)果:
Next Sibling Hello Previous Sibling Once upon a time there were three little sisters; and their names were
五、方法選擇器上面所講的選擇方法都是通過屬性來選擇的,這種方法非常快,但是如果進行比較復(fù)雜的選擇的話,它就比較煩瑣,不夠靈活了。
Beautiful Soup 還提供了一些查詢方法,例如:find_all()和 find()等。
find_all 是查詢所有符合條件的元素。給它傳入一些屬性或文本,就可以得到符合條件的元素,它的功能十分強大。
語法格式如下:
find_all(name , attrs , recursive , text , **kwargs)
find_all 方法傳入 name 參數(shù),根據(jù)節(jié)點名來查詢元素
from bs4 import BeautifulSouphtml = ’’’ <div class='panel'> <div class='panel-heading'> <h4>Hello</h4> </div> <div class='panel-body'> <ul id='list-1'> <li class='element'>Foo</li> <li class='element'>Bar</li> <li class='element'>Jay</li> </ul> <ul id='list-2'> <li class='element'>Foo</li> <li class='element'>Bar</li> </ul> </div> </div>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)for ul in soup.find_all(name=’ul’): print(ul.find_all(name=’li’)) for li in ul.find_all(name=’li’):print(li.string)
結(jié)果如下:
[<li class='element'>Foo</li>, <li class='element'>Bar</li>, <li class='element'>Jay</li>]FooBarJay[<li class='element'>Foo</li>, <li class='element'>Bar</li>]FooBar
從上述示例可以看到,調(diào)用 find_all()方法,name 參數(shù)值為 ul。返回結(jié)果是查詢到的所有 ul 節(jié)點列表類型,長度為 2,每個元素依然都是 bs4.element.Tag 類型。因為都是 Tag 類型, 所以依然可以進行嵌套查詢。再繼續(xù)查詢其內(nèi)部的 li 節(jié)點,返回結(jié)果是 li 節(jié)點列表類型, 遍歷列表中的每個 li,獲取它的文本。
find_all 方法傳入 attrs 參數(shù),根據(jù)屬性來查詢
from bs4 import BeautifulSouphtml = ’’’ <div class='panel'> <div class='panel-heading'> <h4>Hello</h4> </div> <div class='panel-body'> <ul name='elements'> <li class='element'>Foo</li> <li class='element'>Bar</li> <li class='element'>Jay</li> </ul> <ul id='list-2'> <li class='element'>Foo</li> <li class='element'>Bar</li> </ul> </div> </div>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)print(soup.find_all(attrs={’id’: ’list-1’}))print(soup.find_all(attrs={’name’: ’elements’}))
結(jié)果如下:
[<ul name='elements'><li class='element'>Foo</li><li class='element'>Bar</li><li class='element'>Jay</li></ul>][<ul name='elements'><li class='element'>Foo</li><li class='element'>Bar</li><li class='element'>Jay</li></ul>]
從上述示例可以看到,傳入 attrs 參數(shù),參數(shù)的類型是字典類型。比如,要查詢 id 為 list-1 的節(jié)點,可以傳入 attrs={‘id’: ‘list-1’}的查詢條件,得到的結(jié)果是列表形式,包含的內(nèi)容就是符合 id 為 list-1 的所有節(jié)點。符合條件的元素個數(shù)是 1,長度為 1 的列表。對于一些常用的屬性,比如 id 和 class 等,可以不用 attrs 來傳遞。比如,要查詢 id 為 list-1 的節(jié)點 ,可以直接傳入 id 這個參數(shù)。
示例如下:
print(soup.find_all(id=’list-1’))print(soup.find_all(class_=’element’))
上述示例直接傳入 id=’list-1’,就可以查詢 id 為 list-1 的節(jié)點元素了。而對于 class 來 說,由于 class 在 Python 里是一個關(guān)鍵字,所以后面需要加一個下劃線,即 class_=’element’, 返回的結(jié)果依然還是 Tag 組成的列表。
find_all 方法根據(jù)文本來查詢
find_all 方法傳入 text 參數(shù)可用來匹配節(jié)點的文本,傳入的形式可以是字符串,可以是正則表達式對象。
from bs4 import BeautifulSoupimport rehtml = ’’’ <div class='panel'> <div class='panel-body'> <a>Hello, this is a link</a> <a>Hello, this is a link, too</a> </div> </div>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)print(soup.find_all(text=re.compile(’link’)))
運行結(jié)果
[’Hello, this is a link’, ’Hello, this is a link, too’]
上述示例有兩個 a 節(jié)點,其內(nèi)部包含文本信息。這里在 find_all()方法中傳入 text 參數(shù), 該參數(shù)為正則表達式對象,結(jié)果返回所有匹配正則表達式的節(jié)點文本組成的列表。除了 find_all()方法,還有 find()方法,不過后者返回的是單個元素,也就是第一個匹配的元素,而前者返回的是所有匹配的元素組成的列表。
find 方法查詢第一個匹配的元素
from bs4 import BeautifulSoupimport rehtml = ’’’ <<div class='panel'> <div class='panel-heading'> <h4>Hello</h4> </div> <div class='panel-body'> <ul id='list-1'> <li class='element'>Foo</li> <li class='element'>Bar</li> <li class='element'>Jay</li> </ul> <ul id='list-2'> <li class='element'>Foo</li> <li class='element'>Bar</li> </ul> </div> </div>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)# 獲取標(biāo)簽名為ul的標(biāo)簽體內(nèi)容print(soup.find(name=’ul’))# 獲取返回結(jié)果的列表print(type(soup.find(name=’ul’)))# 查找標(biāo)簽中class是’list’print(soup.find(class_=’list’))
結(jié)果如下
<ul id='list-1'><li class='element'>Foo</li><li class='element'>Bar</li><li class='element'>Jay</li></ul><class ’bs4.element.Tag’><ul id='list-1'><li class='element'>Foo</li><li class='element'>Bar</li><li class='element'>Jay</li></ul>
上述示例使用 find 方法返回結(jié)果不再是列表形式,而是第一個匹配的節(jié)點元素,類型依然是 Tag 類型。
六、CSS 選擇器Beautiful Soup 還提供了另外一種選擇器,那就是 CSS 選擇器。使用 CSS 選擇器時,只 需要調(diào)用 select()方法,傳入相應(yīng)的 CSS 選擇器即可。
CSS相關(guān)知識:
#element: id選擇器.
element:類選擇器
tag tag:派生選擇器
通過依據(jù)元素在其位置的上下文關(guān)系來定義樣式,你可以使標(biāo)記更加簡潔。
from bs4 import BeautifulSoupimport rehtml = ’’’ <div class='panel'> <div class='panel-heading'> <h4>Hello</h4> </div> <div class='panel-body'> <ul id='list-1'> <li class='element'>Foo</li> <li class='element'>Bar</li> <li class='element'>Jay</li> </ul> <ul id='list-2'> <li class='element'>Foo</li> <li class='element'>Bar</li> </ul> </div> </div>’’’# 獲取bs4解析對象,使用解析器:lxml,html:解析內(nèi)容soup = BeautifulSoup(html, ’lxml’)# 獲取class=panel標(biāo)簽下panel_heading,類選擇器print(soup.select(’.panel .panel-heading’))# 派生選擇器print(soup.select(’ul li’))# id選擇器+類選擇器lis = soup.select(’#list-2 .element’)for l in lis: print(’GET TEXT’, l.get_text()) print(’String:’, l.string)
結(jié)果如下
[<div class='panel-heading'><h4>Hello</h4></div>][<li class='element'>Foo</li>, <li class='element'>Bar</li>, <li class='element'>Jay</li>, <li class='element'>Foo</li>, <li class='element'>Bar</li>]GET TEXT FooString: FooGET TEXT BarString: Bar
上述示例,用了 3 次 CSS 選擇器,返回的結(jié)果均是符合 CSS 選擇器的節(jié)點組成的列表。 例如,select(‘ul li’)則是選擇所有 ul 節(jié)點下面的所有 li 節(jié)點,結(jié)果便是所有的 li 節(jié)點組成的列表。要獲取文本,當(dāng)然也可以用前面所講的 string 屬性。此外,還有一個方法,那就是 get_text()。
到此這篇關(guān)于Python爬蟲進階之Beautiful Soup庫詳解的文章就介紹到這了,更多相關(guān)Python Beautiful Soup庫詳解內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 詳解CSS開發(fā)過程中的20個快速提升技巧2. 一篇文章帶你了解JavaScript-語句3. .Net Core使用Coravel實現(xiàn)任務(wù)調(diào)度的完整步驟4. 常見 PHP ORM 框架與簡單代碼實現(xiàn)5. asp讀取xml文件和記數(shù)6. XML 取得元素的字符數(shù)據(jù)7. Ajax實現(xiàn)動態(tài)顯示并操作表信息的方法8. 如何使用ASP.NET Core 配置文件9. .Net core 的熱插拔機制的深入探索及卸載問題求救指南10. ASP+ajax實現(xiàn)頂一下、踩一下同支持與反對的實現(xiàn)代碼

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備